ترنسفورمر در مقاله Attention is All You Need معرفی شد. پیاده سازی آن در فریمورک TensorFlow در این این لینک قابل دسترسی است. در این پست سعی داریم تا یک نگاه کلی و در عین حال به دور از پیچیدگی به مدل ترنسفورمر، اجزای آن و نحوه کارکرد آن داشته باشیم.
نگاه سطح بالا به ترنسفورمر
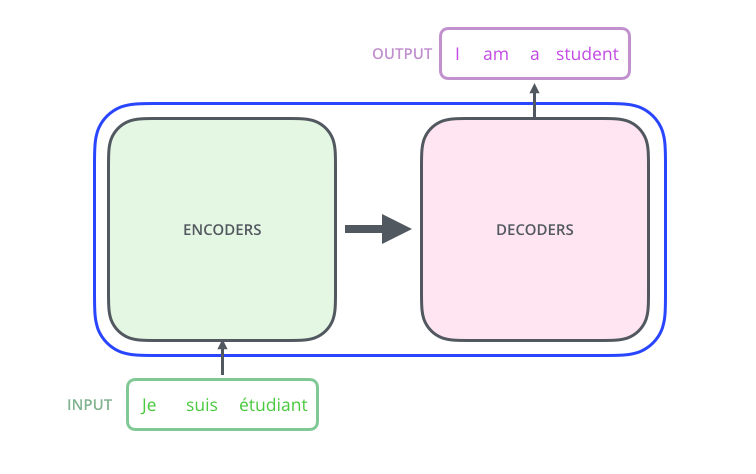
ترنسفورمر را میتوان به صورت یک جعبه سیاه در نظر گرفت. مانند یک مدل ترجمه زیانی که از یک طرف جملهای به آن وارد و در طرف دیگر یعنی خروجی جملهای دیگر به عنوان ترجمه تولید میشود.

اگر یک قدم جلوتر برویم و اصطلاحاً در جعبه سیاه را باز کنیم، یک رمزنگار و رمزگشا خواهیم دید که به شکل زیر به هم متصل شدهاند.
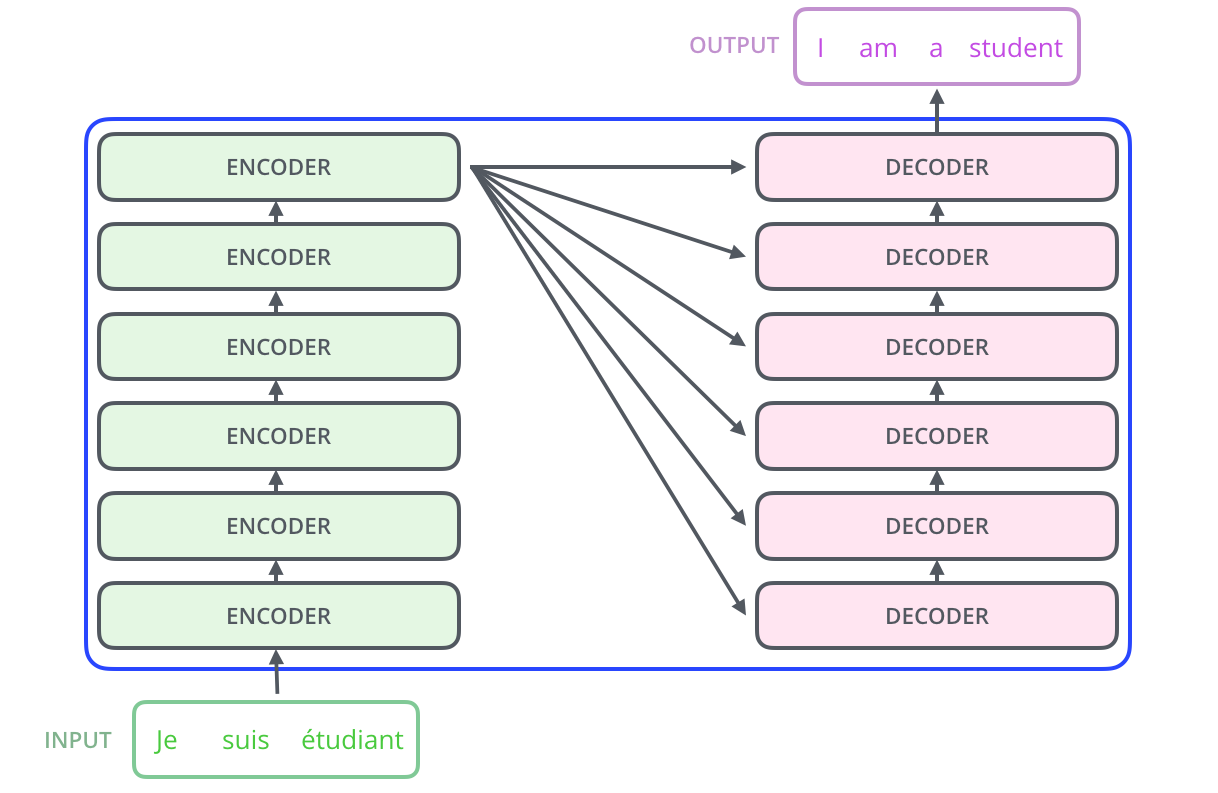
بخش رمزنگار خود از ۶ رمزنگار کوچک تشکیل شده است (دلیلی برای ۶تا وجود ندارد. شما میتوانید هر چندتا در مدل خود داشته باشید). مجموعه این رمزنگارهای کوچک در قالب یک پشته یا استک، بلوک رمزنگار را میسازند. در مقابل و در بخش رمزگشا همین تعداد رمزگشا کوچک داریم که با استک خروجیهایشان خروجی نهایی بلوک رمزگشا بدست میآید.
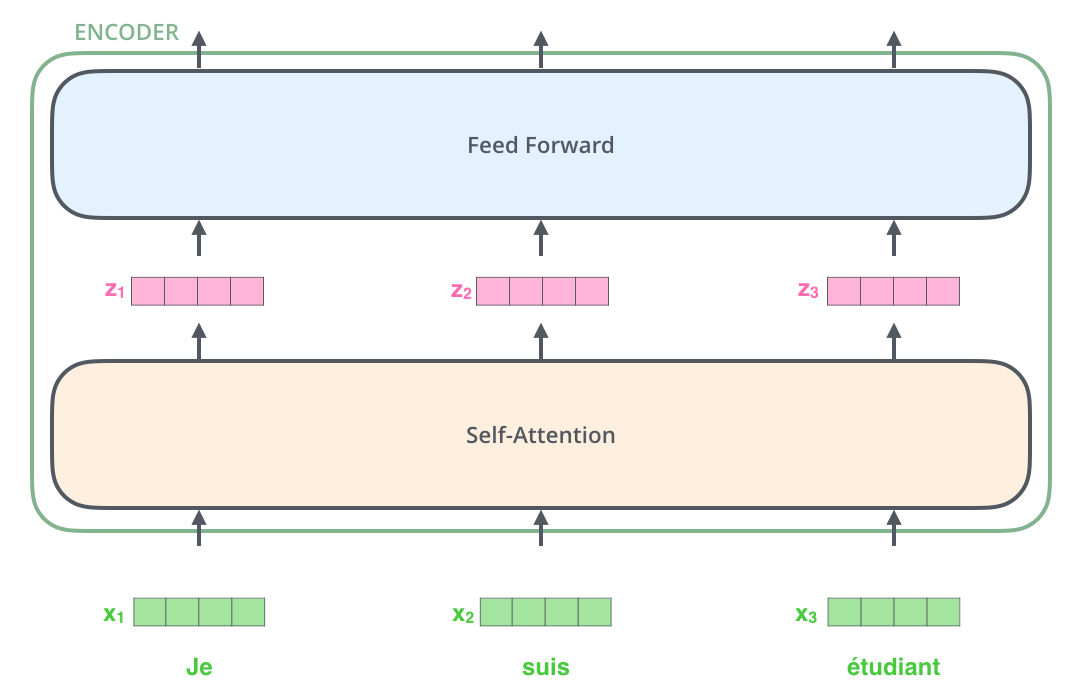
رمزنگارها ساختار یکسانی دارند اما هر کدام وزنهای مختص به خود را دارند. هر کدام از این رمزنگارها دارای دو بخش است:
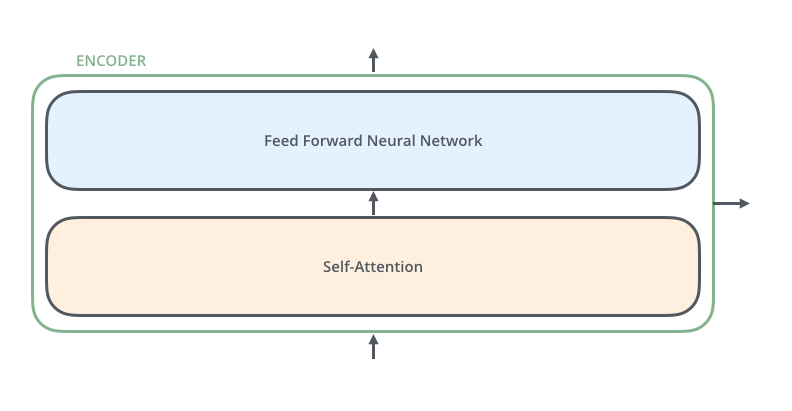
ورودیهای رمزگشا ابتدا از یک لایه خود-توجه عبور میکنند. لایه خود-توجه به رمزنگار کمک میکند تا در هنگام رمزنگاری هر کلمه، به کلمات دیگر موجود در جمله ورودی نیز توجه کند. در ادامه توضیحات مفصلتری در مورد این بخش آورده خواهد شد.
خروجیهای لایه خود توجه به یک شبکه feed-forward ورودی داده میشوند. در واقع بردار مربوط به هر کلمه ورودی به صورت مجزا به این شبکه ورودی داده میشود. هر رمزگشا یا دیکودر نیز، مانند رمزنگار، دو لایه مذکور را دارد. با این تفاوت که بین این دو لایه یک لایه توجه وجود دارد که به رمزگشا کمک میکند تا تمرکز خود را بر روی بخشهای مربوط جمله ورودی قرار دهد (شبیه مکانیزم توجه در مدلهای sequence2sequence).
شرح نحوه محاسبه خروجی با استفاده از مثال
تا اینجا با بخشهای اصلی ترنسفورمر به صورت کلی آشنا شدیم. حال برای بررسی دقیقتر ببینیم چه عملیاتی روی تنسورهای ورودی انجام میشود تا خروجی مورد نظر ما بدست آید.
همانطور که میدانید برای آنکه کلمات را به یک بردار قابل درک برای یک شبکه عصبی تبدیل کنیم، از یک embedding algorithm استفاده میکنیم.

به هر کلمه یک بردار با سایز ۵۱۲ اختصاص داده میشود. برای سادگی ما این بردارها را به شکل بالا نمایش میدهیم.
هر کدام از رمزنگارها با دریافت یک لیست از بردارهای ۵۱۲تایی، خروجی مربوط به خود را تولید میکند. لازم به ذکر است اولین رمزنگار در توالی رمزنگارها لیستی از بردارهای امبدینگ را دریافت میکند و خروجی آن نیز لیستی به همان طول از بردارهای ۵۱۲تایی خواهد بود. لیست خروجی این رمزنگار به رمزنگار بعدی در توالی ورودی داده میشود. طول لیست مذکور یکی از ابرپارامترهای مدل ترنسفورمر است که معمولاً ما آن را به اندازه طول بزرگترین جمله موجود در مجموعه داده انتخاب میکنیم.
در این مرحله میتوانیم یک ویژگی کلیدی از ترنسفورمر را مشاهده کنیم. هر کلمه مسیر مخصوص به خود را در هنگام عبور از رمزنگار طی می کند. چون در لایه خود توجه بین بردارهای کلمات وابستگی محاسباتی وجود دارد امکان پردازش مستقل کلمه وجود ندارد و بایستی بردار تمامی کلمات همزمان ورودی داده شوند. اما در بخش feed-forward چنین وابستگی وجود ندارد و بردار بدست آمده برای هر کلمه میتواند به طور مستقل به این شبکه ورودی داده شود و در خروجی بردار جدید برای آن بدست آید. لذا امکان پردازش موازی برای این قسمت وجود دارد.
در مرحله بعد قصد داریم تا با استفاده از یک جمله کوتاهتر ببینیم چه اتفاقی در هر زیرلایه رمزنگار میافتد.
رمزنگار
همانطور که پیشتر گفتیم رمزنگار با دریافت لیستی از بردارها آنها را از دو لایه خود-توجه و سپس feed-forward عبور داده و خروجی را به انکودر بعدی که در توالی قرار دارد میدهد.
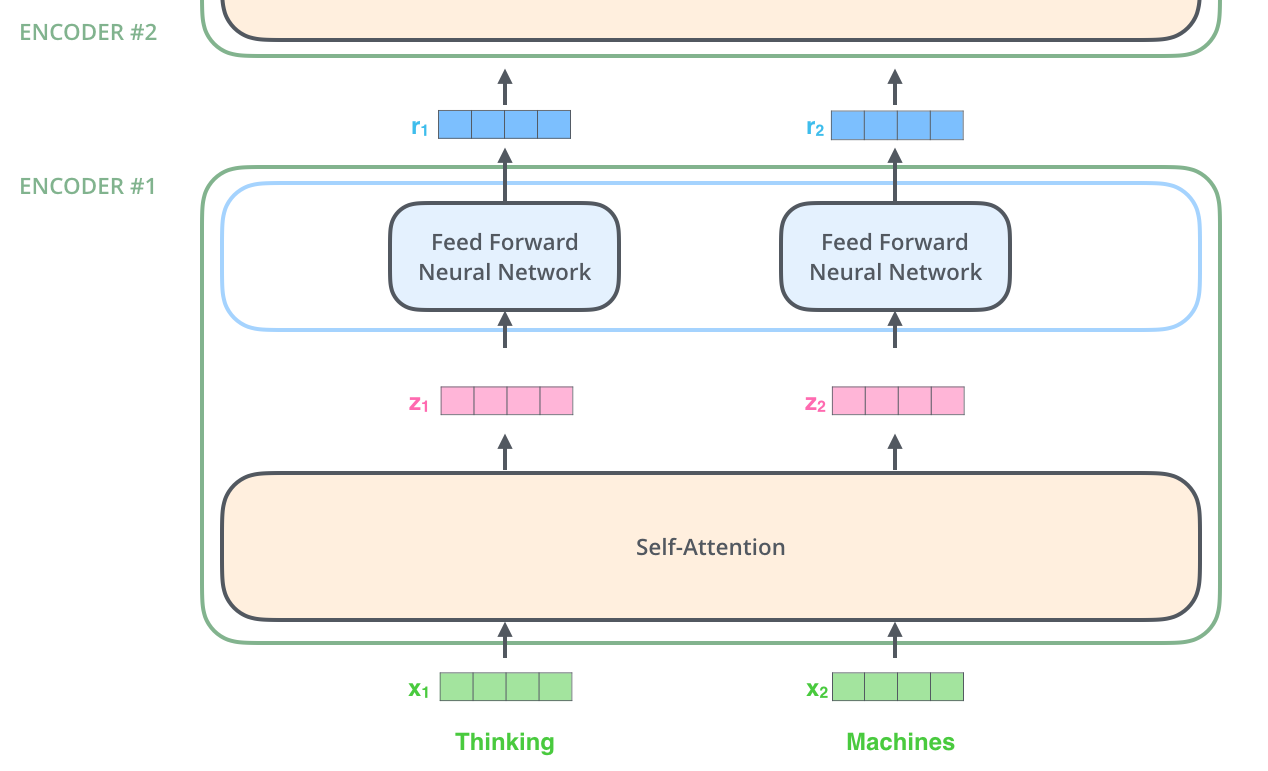
هر کلمه که در مکانی مشخص از جمله قرار دارد از لایه خود توجه عبور میکند. سپس هر کدام از بردارها به صورت مستقل از یک شبکه feed-forward عبور میکند.
نگاهی کلی به مکانیزم خود توجه
فرض کنید نمونه زیر جملهای باشد که ما قصد ترجمه آن را داریم:
“The animal didn't cross the street because it was too tired”
برای ترجمه صحیح این جمله ابتدا باید مشخص کرد که کلمه “it” به چه چیزی اشاره میکند، خیابان یا حیوان. تشخیص این امر برای ما انسانها کار سادهای است ولی برای الگوریتم به این سادگیها نیست.
مکانیزم خود-توجه به مدل ترنسفورمر کمک میکند تا در هنگام پردازش کلمه “it” آن را به حیوان نسبت دهد.
به بیان مفهومیتر مکانیزم خود توجه به مدل کمک میکند تا هنگام رمزنگاری هر کلمه از جمله به کلمات دیگر همان جمله هم توجه کند و به رمزنگاری بهتر و دقیقتری برای این کلمه دست یابد.
اگر با RNNها آشنا باشید میدانید که این مدلها از یک وضعیت مخفی برای حفظ اطلاعاتی از کلمات یا بردارهای قبلی که پردازش کردهاند استفاده میکنند و این اطلاعات را با بردار فعلی که در حال پردازش است ترکیب میکنند. در ترنسفورمرها، روش خود-توجه جایگزین این مکانیزم میشود. به این معنا که مدل از طریق خود-توجه میتواند ارتباطات بین کلمات مختلف در جمله را در نظر بگیرد و از این ارتباطات در هنگام پردازش هر کلمه استفاده کند.

همانطور که مشاهده میشود در هنگام رمزنگاری کلمه “it” در رمزنگار پنجم (از 6)، مکانیزم خود-توجه به بردار کلمات “The Animal” وزن بیشتری اختصاص میدهد و آنها را در پروسه رمزنگاری کلمه “it” بیشتر دخالت میدهد.
حتما به Tensor2Tensor notebook سر بزنید. در آنجا میتوانید خروجی لایههای مختلف یک مدل ترنسفورمر را به صورت تعاملی مشاهده و بررسی کنید.
نگاهی دقیقتر به مکانیزم خود-توجه
در این بخش اول نحوه محاسبه خروجی لایه مکانیزم خود-توجه را توضیح میدهیم. میخواهیم ببینیم چه عملیاتی روی بردارهای ورودی انجام شده تا بردارهای خروجی لایه مذکور بدست آید. بعد از آن نیز مراحل پیادهسازی ماتریسی آن را شرح میدهیم.
قدم اول در محاسبه خروجی لایه خود-توجه، ساخت 3 بردار “Key”،“Query” و “Value” به ازای هر بردار کلمه ورودی است. همانطور که قبلا گفتیم در اینجا منظور از بردار کلمات همان بردار امبدینگ کلمات است. هر کدام از این سه بردار (Key, Query, value) وزن مختص به خود را دارد که در طول آموزش مدل تنظیم میشود. این بردارهای وزن با ضرب در بردار امبدینگ هر کلمه مقداردهی میشوند.
لازم به ذکر است که ابعاد بردارهای سهگانه مذکور کمتر از ابعاد امبدینگ کلمات است و برابر با 64 است. البته این اندازه میتواند بسته به انتخاب شما در هنگام طراحی مدل تغییر کند.
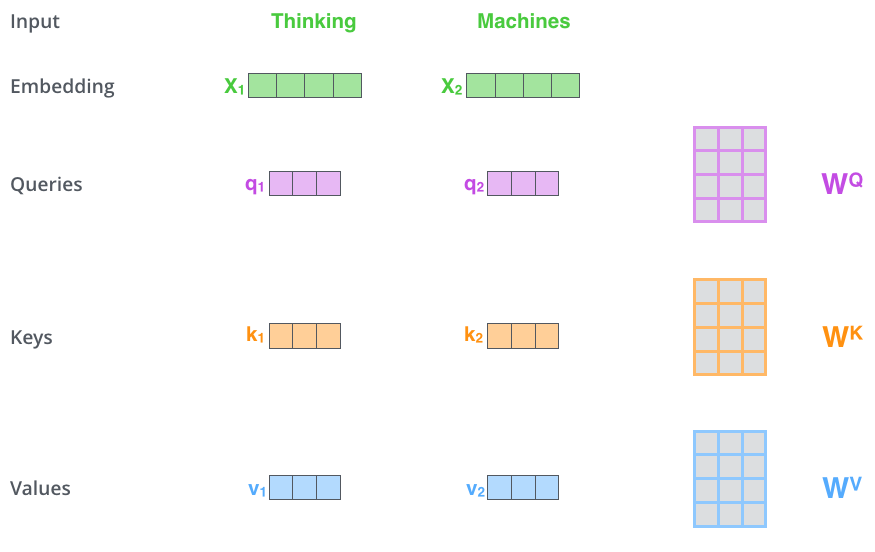
ضرب x1 در ماتریس وزن WQ، بردار q1 را تولید میکند که همان بردار “query” مرتبط با آن کلمه است. در نهایت، ما یک افکنش از “query”، یک “key” و یک “value” برای هر کلمه در جمله ورودی ایجاد میکنیم.
بردارهای “Query”،“Key” و “Value” دقیقا چه تعریف و نقشی دارند؟ این بردارها انتزاع و به اصطلاح abstraction هستند که از طریق آنها مکانیزم توجه پیادهسازی و اعمال میشود. در ادامه در مورد نحوه محاسبه آنها توضیح میدهیم تا نقش هرکدام برایتان روشنتر شود.
قدم دوم در محاسبه خروجی خود-توجه محاسبه یک امتیاز برای هر کلمه نسبت به کلمات دیگر موجود در جمله است. فرض کنید جمله ورودی ما : “Thinking Machines” باشد. ما میخواهیم خروجی خود-توجه را برای کلمه اول یعنی “Thinking” محاسبه کنیم. بدین منظور لازم است تا به تمام کلمات موجود در جمله یک امتیاز نسبت به کلمه مورد بررسی اختصاص دهیم. جمع این امتیازها بایستی برابر 1 شود. این امتیازها در واقع مشخص میکند هر کلمه در جمله چه سهمی در محاسبه انکودینگ کلمه مورد نظر ما داشته باشد.
برای محاسبه امتیاز هر کلمه نسبت به “Thinking”، بردار “Query” این کلمه که در اینجا q1 است را در بردار “Key” آن ضرب میکنیم. مثلا در اینجا برای محاسبه امتیاز کلمه “Thinking” نسبت به خودش بایستی ضرب داخلی q1 و k1 را محاسبه کنیم. به همین ترتیب برای محاسبه امتیاز “Machines” نسبت به “Thinking” بایستی q1.k2 را محاسبه کنیم. این عملیات در شکل زیر نمایش داده شده است.
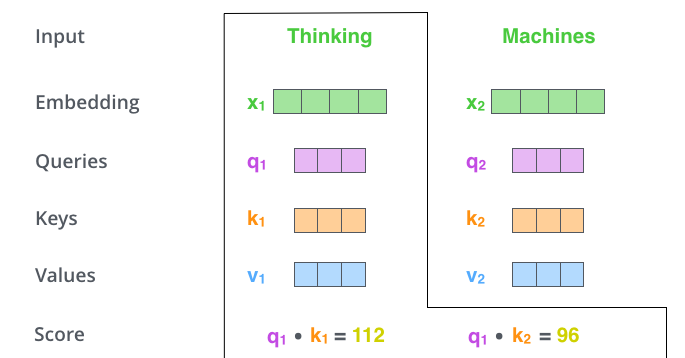
قدم سوم یکی تقسیم امتیازهای بدست آمده از قدم اول بر مجذور اندازه بردار “Key” است. در اینجا این مقدار برابر با 8 میشود. قدم چهارم هم اعمال Softmax به امتیازات است. این مقدار امتیازها را نرمالیزه و جمع آنها را برابر با 1 قرار میدهد.
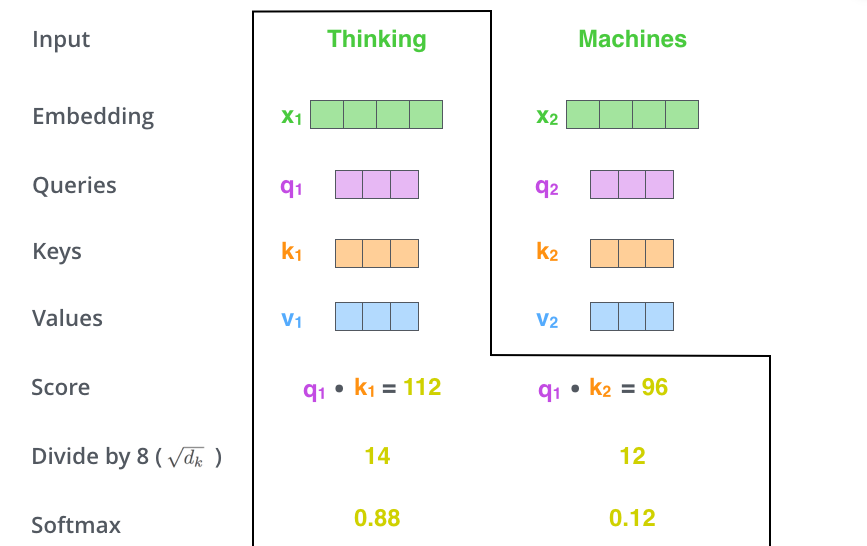
امتیاز اختصاص داده شده به هر کلمه میزان ارتباط آن را با کلمه مورد بررسی مشخص میکند و به همین میزان در محاسبه بردار انکودینگ کلمه مورد نظر نقش دارد. طبعا این امتیاز برای خود کلمه مورد بررسی بیشترین مقدار را دارد.
قدم پنجم، ضرب بردار Value هر کلمه در امتیاز Softmax آن است. قدم ششم، جمع بردارهای وزندهی شده شده است. با این کار بردار خروجی لایه خود-توجه برای کلمه “Thinking” بدست میآید.
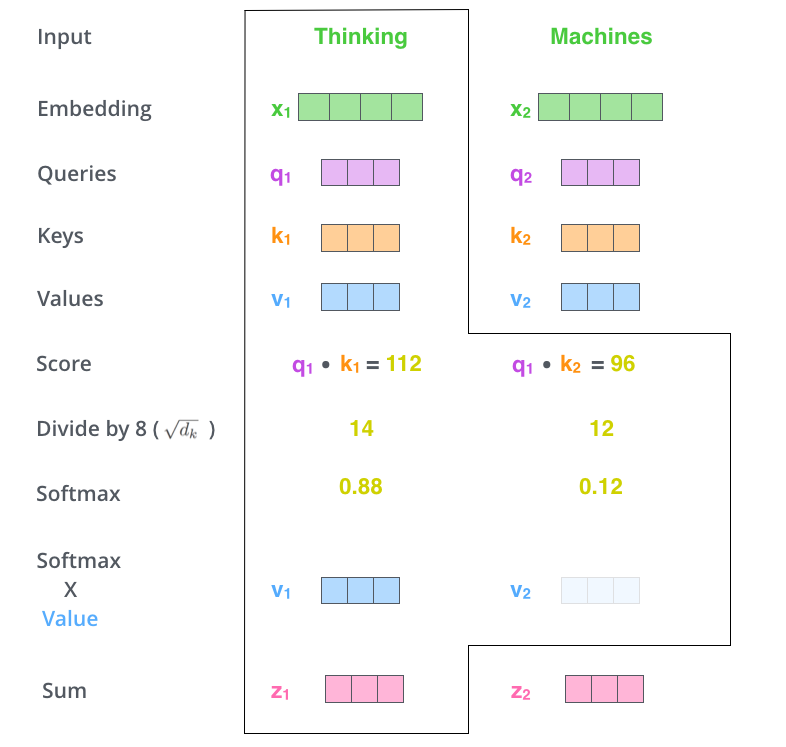
خروجی بدست آمده در مرحله بعد به شبکه feed-forward ورودی داده میشود. در بخش بعد خواهیم دید این عملیات چطور به صورت ماتریسی (برای پردازش سریعتر) پیادهسازی میشود.
محاسبه ماتریسی خود-توجه
ابتدا، بردارهای Query، Key، و Value محاسبه میشوند. طبق شکل زیر اگر بردارهای امبدینگ کلمات را در ماتریس X قرار دهیم، با ضرب این ماتریس در ماتریسهای وزن WQ، WK، و WV (که در طول آموزش شبکه یاد گرفته میشوند)، میتوان بردارهای Query، Key، و Value را برای هر کلمه به دست آورد.
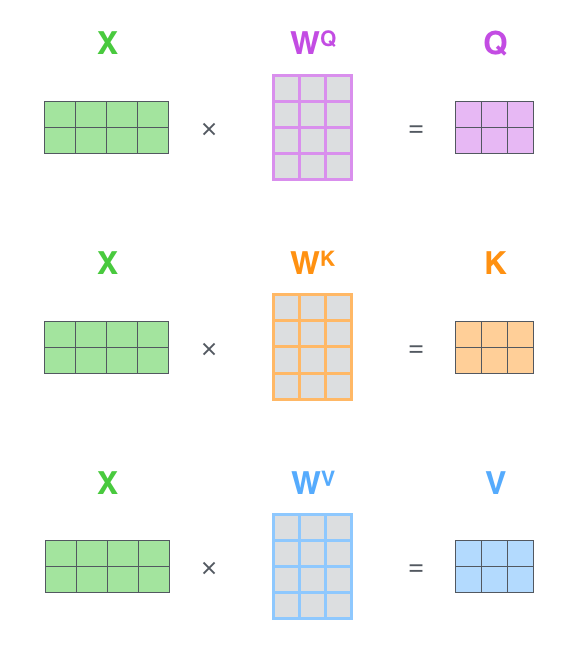
در ماتریس X، هر ردیف نمایانگر بردار امبدینگ یک کلمه از جمله ورودی است. در اینجا، ابعاد ماتریس امبدینگ (برای مثال 512) بیشتر از ابعاد بردارهای Q، K، و V (در اینجا 64) است.
در نهایت، به دلیل اینکه این محاسبات به صورت ماتریسی انجام میشود، مراحل 2 تا 6 که در بخش قبلی توضیح داده شدند، در فرمول زیر خلاصه میشوند:
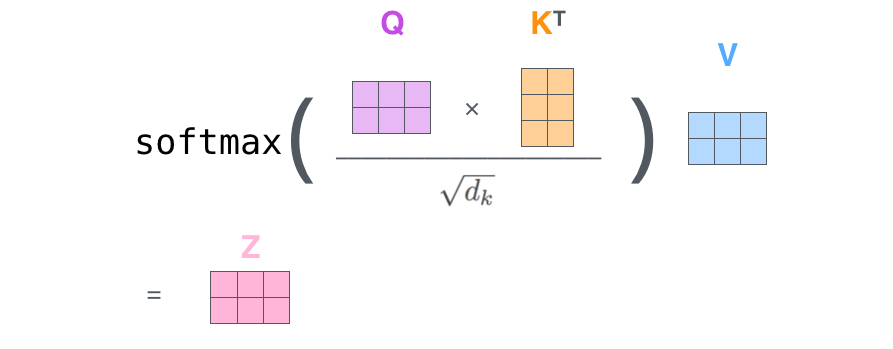
اژدهای چند سر
مقاله مورد بررسی برای بهبود عملکرد لایه خود-توجه مکانیزم جدیدی به نام توجه “چند-سر” یا همان “Multi-Headed” را معرفی کرده است. این مکانیزم عملکرد لایه خود توجه را از دو منظر بهبود میبخشد:
-
همانطور که در مثال قبلی دیدیم، بردار
z1ترکیبی وزندار از بردارهای تمامی کلمات جمله بود. در چنین وضعیتی، ممکن است وزن کلمهای که برای آن بردار خود-توجه محاسبه میشود، آنقدر بزرگ باشد که اثر کلمات دیگر را کاهش دهد. مکانیزم چند-سر کمک میکند تا مدل بتواند به بخشهای مختلف جمله توجه کند و اثر کلمات دیگر نیز در نظر گرفته شود. -
این مکانیزم به ما این امکان را میدهد که به جای داشتن یک مجموعه سهتایی Query، Key و Value، چندین مجموعه از این سه بردار را داشته باشیم. در مدل ترنسفورمر، از 8 سر توجه استفاده میشود، بنابراین 8 مجموعه برای هر لایه انکودر/دیکودر خواهیم داشت که هر کدام یک زیرفضا برای مکانیزم توجه ایجاد میکند. این تنوع در زیرفضاها باعث میشود مدل اطلاعات بیشتری را از زوایای مختلف بررسی کند.
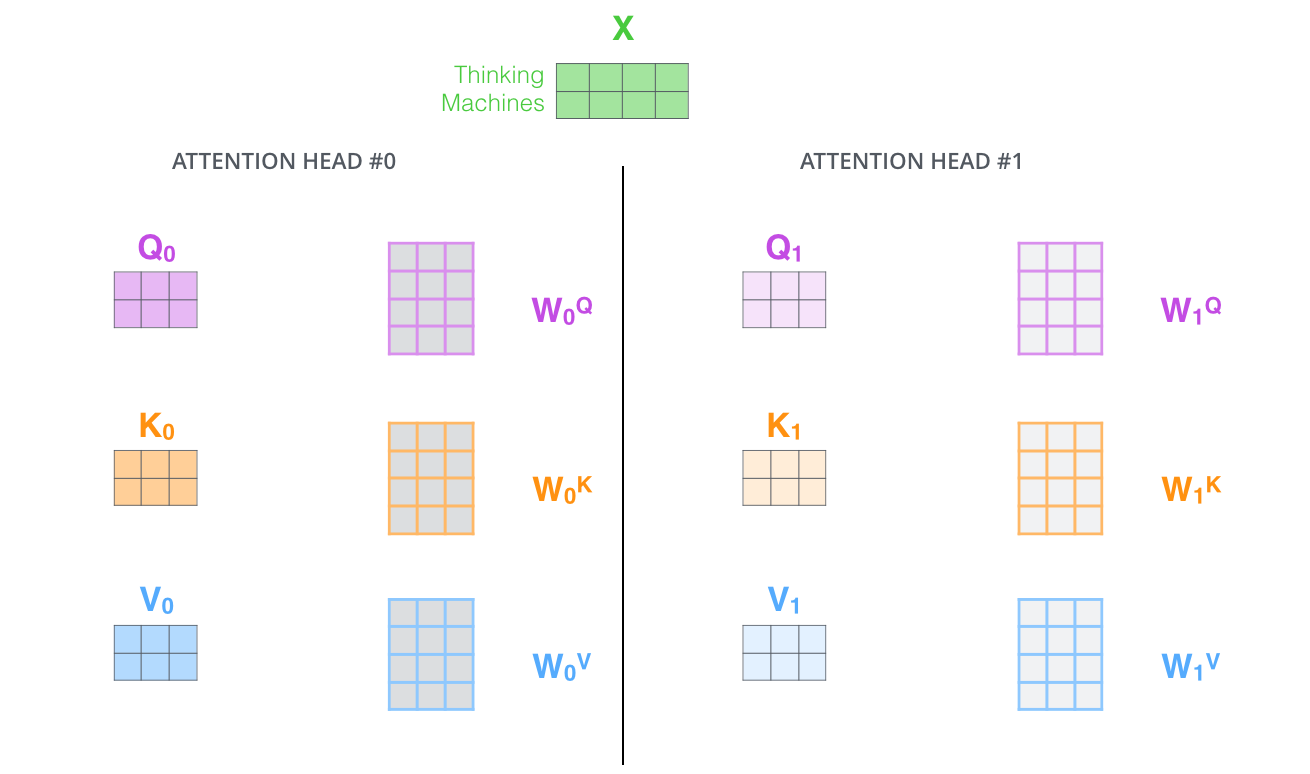
با کمک توجه چند-سر، ما به ازای هر سر ماتریس وزن جداگانهای برای بردارهای Q, K, V داریم که در طول آموزش منجر به بدست آمدن ماتریسهای متفاوتی برای Q, K, V میشوند. مانند قبل با ضرب ماتریسی X با ضرایب بردارهای سهگانه یعنی WQ, WK, WV ماتریسهای Q, K, V بدست میآیند.
با توجه به اینکه 8 سر برای محاسبه خود توجه داریم، اگر 8 بار با ماتریسهای وزن متفاوت محاسبات لایه خود توجه را مانند توضیحات گذشته انجام دهیم به 8 ماتریس متفاوت Z خواهیم رسید.
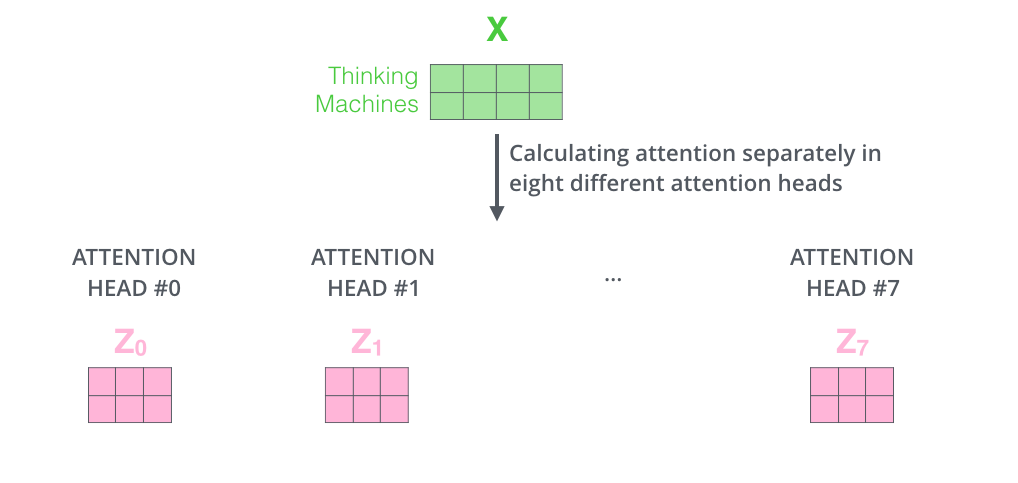
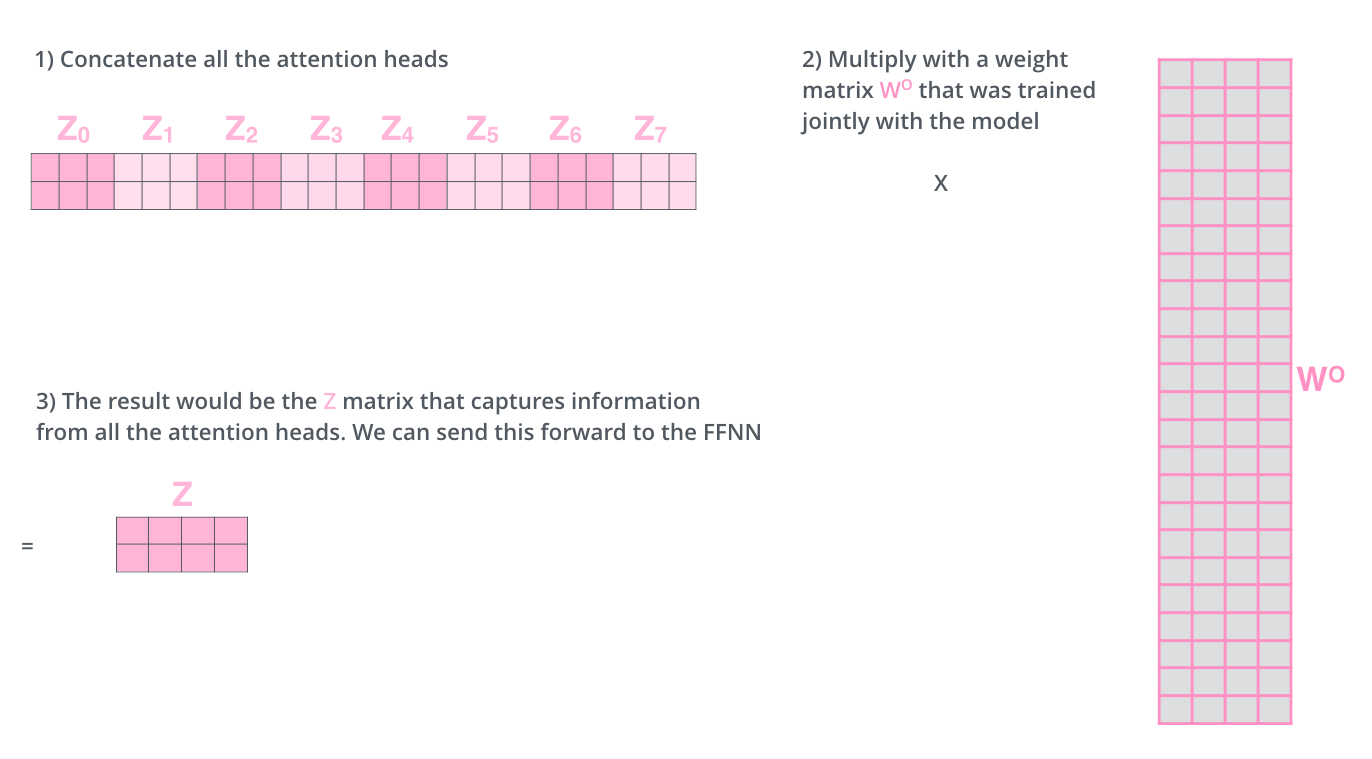
تا اینجا ما 8 ماتریس مختلف برای Z بدست آوردیم که هرکدام ما وزنهای متفاوتی بردار خود توجه کلمات را محاسبه کردهاند. در مرحله بعد بایستی بردار Z را به لایه feed-forward ورودی بدهیم. اما چالش اینجاست که لایه خود توجه انتظار یک بردار z را به عنوان ورودی دارد. پس ما به راهی نیاز داریم تا این 8 ماتریس را در به گونهای در یک ماتریس ترکیب کنیم. اما سوال اینجاست چونه این کار را انجام دهیم؟
جواب این است که ابتدا این 8 ماتریس را با هم concat میکنیم. سپس ماتریس بدست آمده را در یک بردار وزن جدید به نام WO ضرب میکنیم. این کار باعث میشود تا با ترکیب بردارهای مختلفی که برای Z بدست آوردیم یک بردار Z داشته باشیم. نکته جالب اینجاست که شبکه نحوه ترکیب این بردارها با هم را در طول آموزش یاد میگیرد.
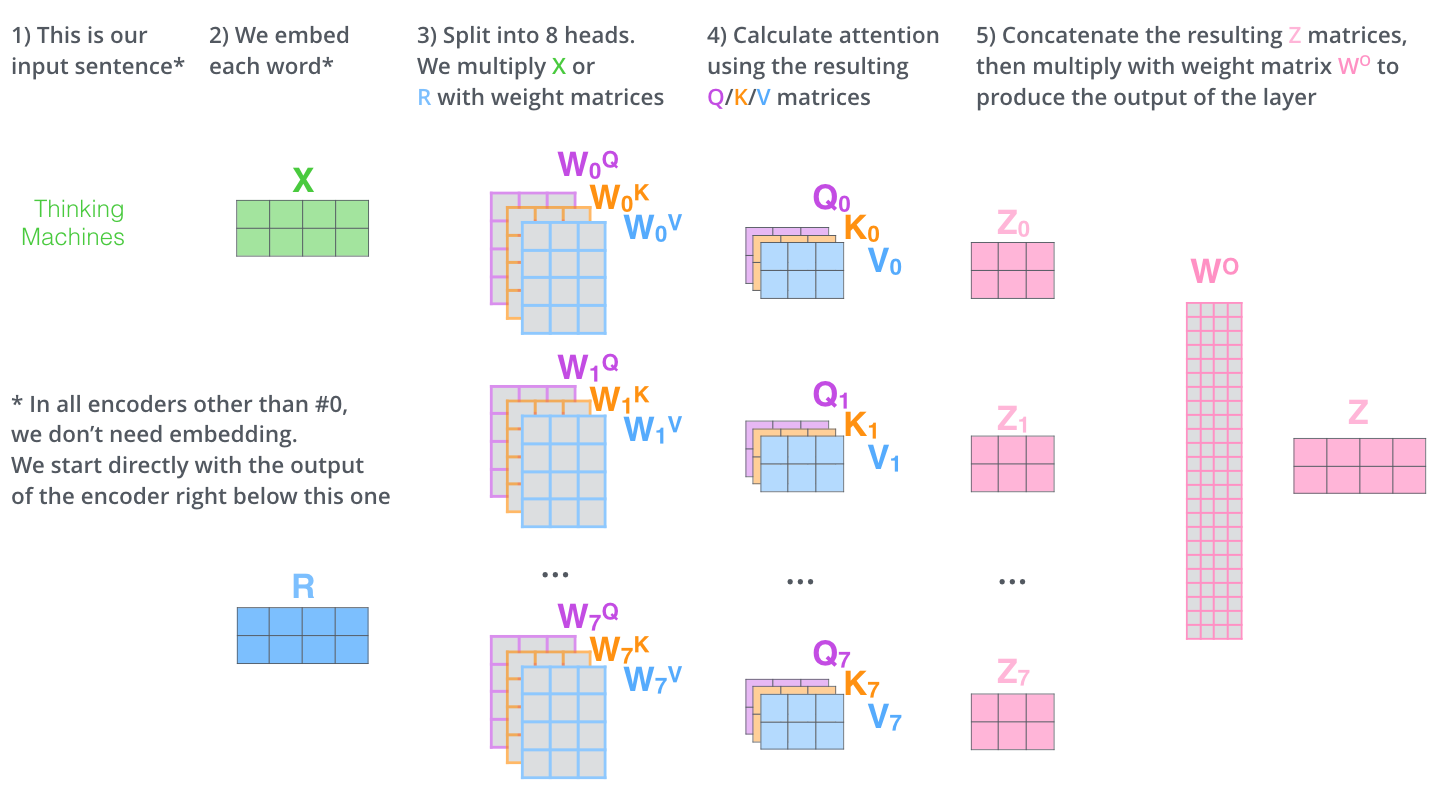
خب این هم از مکانیزم خود-توجه و نحوه محاسبه آن. شکل زیر همه چیزهایی که تا الان گفتیم را جمعبندی میکند:
حالا که با head های توجه آشنایی پیدا کردیم، بیایید دوباره به مثال قبل نگاه کنیم تا ببینیم در هنگام encode کلمه “it” هر کدام از سرها به چه بخشهایی از جمله بیشتر توجه میکنند:

حین encode کلمه “it” یک head بیشترین توجه را روی “the animal” دارد در حالی که یک سر دیگر بیشترین توجه را روی “tired” دارد. به عبارتی representation مدل از کلمه “it” تحت تاثیر representation های “animal” و “tired” قرار دارد.
حال اگر به وزنهای همه 6 سر نگاه کنیم وصف روابط سختتر میشود.
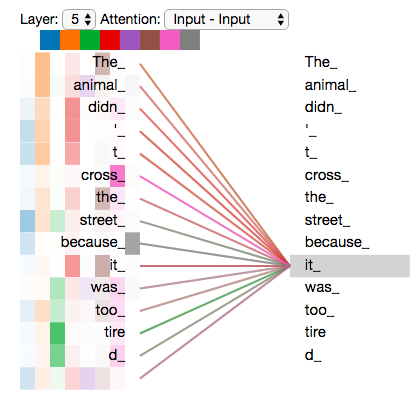
حفظ ترتیب در جمله با استفاده از Positional Encoding یا رمزنگاری مکانی
حال نوبت به این میرسد تا ببینیم مدل چگونه ترتیب کلمات در جمله ورودی را در نظر میگیرد.
بدین منظور ترنسفورمر یک بردار به هر embedding جمله ورودی اضافه میکند. این بردارها از یک الگوی مشخص که مدل در حین آموزش یاد میگیرد، پیروی میکنند. این امر به مدل توانایی درک مکان کلمات مختلف جمله و همچنین فاصله آنها از یکدیگر را میدهد. درک شهودی این است که با اضافه کردن این بردارها تفاوت معنیداری در فاصله بردار embedding کلمات جمله ایجاد میکند که در هنگام بدست آوردن بردارهای K/Q/V اثرگذار است.
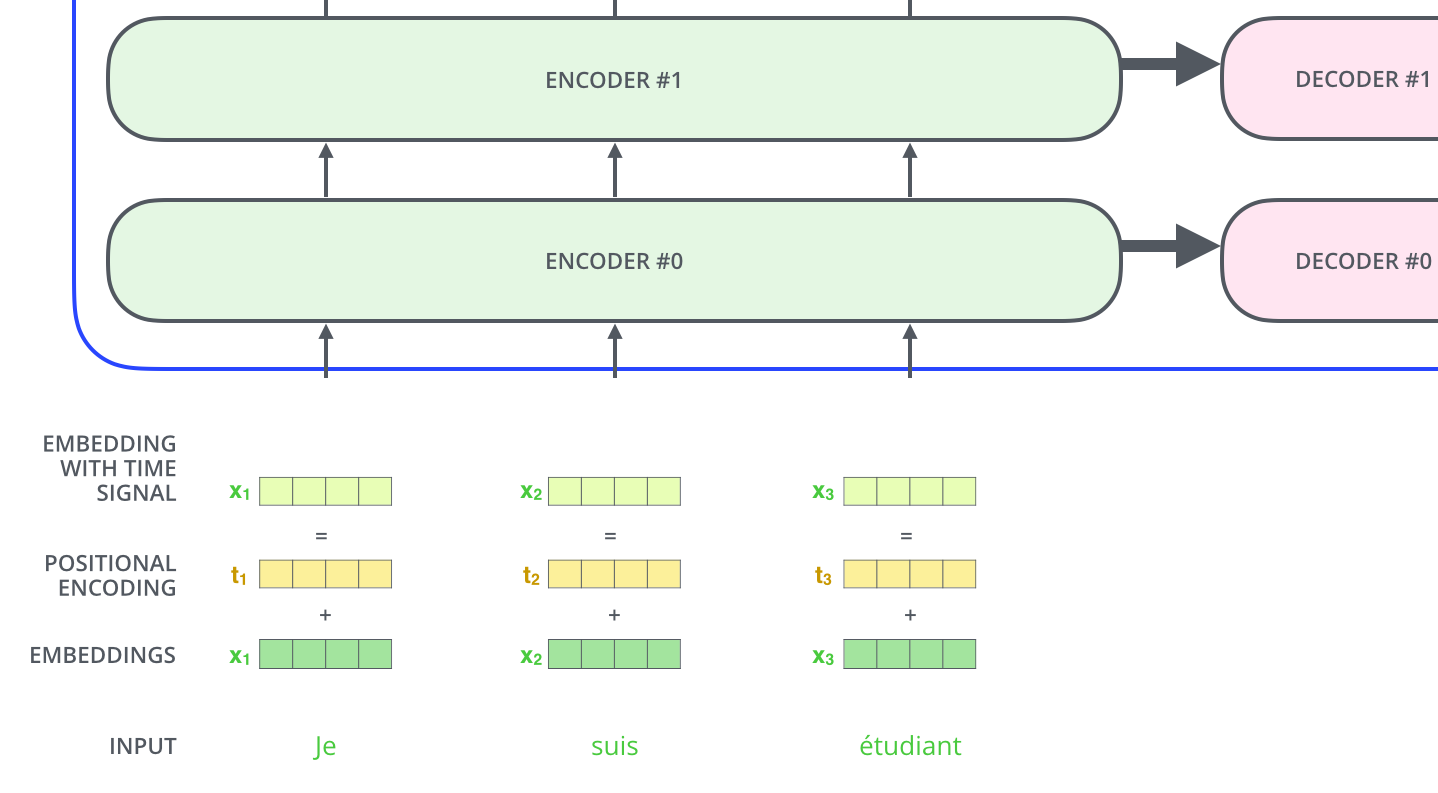
برای اینکه به مدل حسی از ترتیب کلمات بدهیم، بردارهای رمزنگاری مکانی را اضافه میکنیم. بردارهایی که پس از آموزش مقادیر آنها از یک الگوی مشخصی پیروی میکند.
اگر فرض کنیم که بردار embedding کلمات ابعادی برابر با 4 دارد، بردارهای رمزنگاری مکانی به شکل زیر خواهند بود:
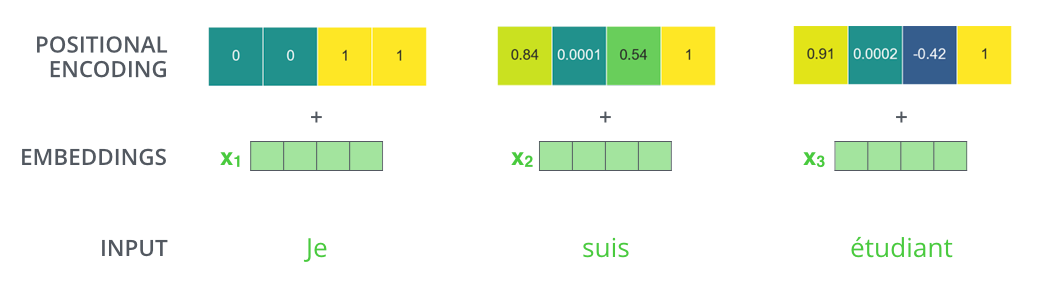
این الگو که راجع بهش صحبت کردیم میتواند چه شکلی باشد؟
با توجه به شکلی که در ادامه آمده است، هر ردیف در تنسور positional encoding متناظر با رمزنگاری مکانی بردار embedding یک کلمه در جمله ورودی است. بنابراین اولین ردیف برداری است که باید به embedding اولین کلمه جمله اضافه کنیم. اگر ابعاد بردار embedding کلمات را 512 در نظر بگیریم بردار مکان آن نیز ابعادی یکسان خواهد داشت و مقادیر آن بین -1 تا 1 خواهد بود.
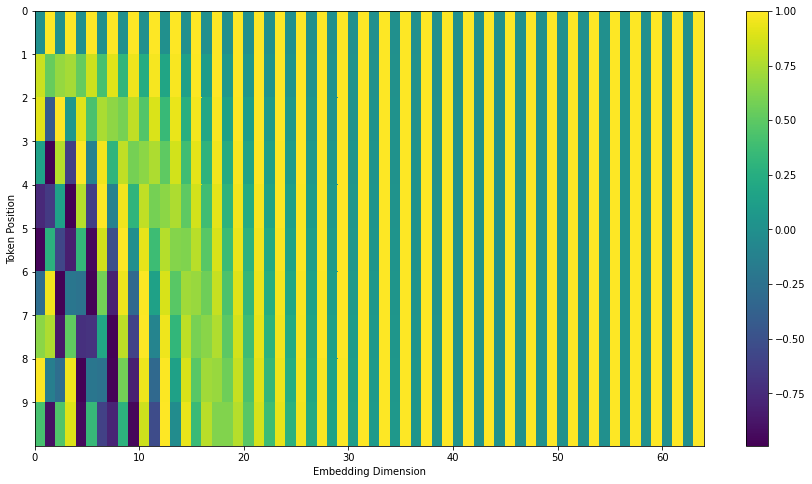
فرمول محاسبه رمزنگاری مکانی در بخش 3.5 مقاله توضیح داده شده است. کد تولید این رمزنگاری در اینجا قرار دارد. قطعا راههای دیگری برای محاسبه رمزنگاری مکانی وجود دارد. برای نمونه تابع get_timing_signal_1d() در کدهای مربوط به Transformer2Transformer عملیات رمزنگاری مکانی را انجام میدهد. مزیت روش معرفی شده در قابلیت مقیاسپذیری آن به جملات با طول دلخواه است. یعنی پس از آموزش مدل با جملههایی با طول مشخص در زمان آزمون مدل توانایی پذیرش جملات طولانیتر را نیز دارد. شکل زیر نمونهای از بردارهای تولید شده توسط این روش را نشان میدهد:
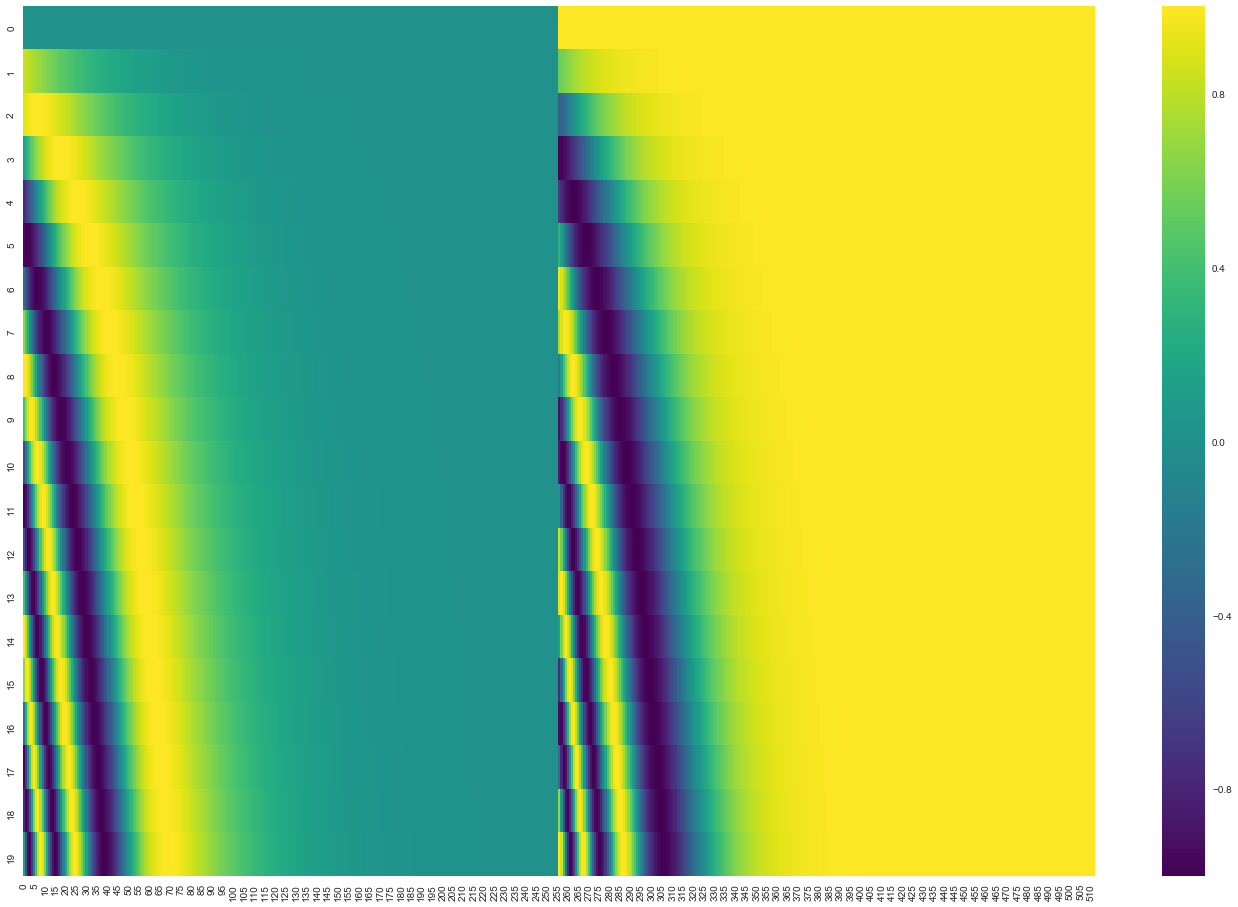
یک مثال واقعی از رمزنگاریهای مکانی برای 20 کلمه (شامل 20 ردیف) با سایز embedding 512 (512 ستون)
اتصالات بازگشتی
یکی از جزئیات دیگر در مدل Transformer که بایستی به آن اشاره کرد، وجود اتصالات بازگشتی در هر زیرلایه انکودر (شامل خود-توجه، شبکه feed-forward) است. به دنبال آن نیز عملیات layer-normalization انجام میشود.
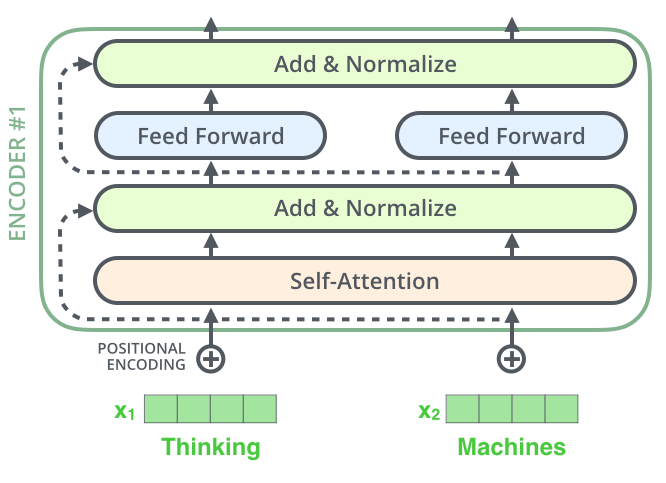
شکل زیر عملیاتی را که در حین محاسبه بردارهای خود توجه روی بردارها انجام میشود در لایه Add and Normalize را نشان میدهد.
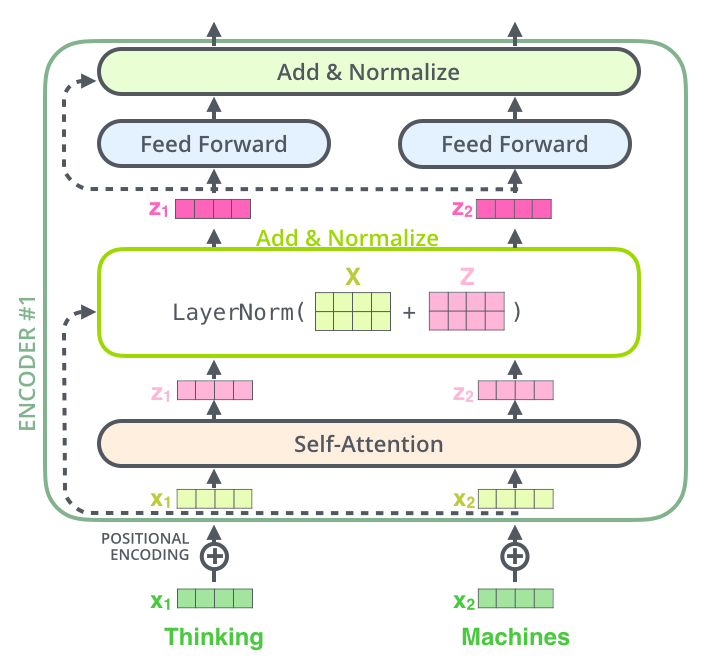
این ساختار در بخش رمزگشا یا decoder نیز صادق است. اگر فرض کنیم ترنسفورمر متشکل از یک رمزنگار و رمزگشا باشد، شکل زیر ساختار آن را نشان میدهد.
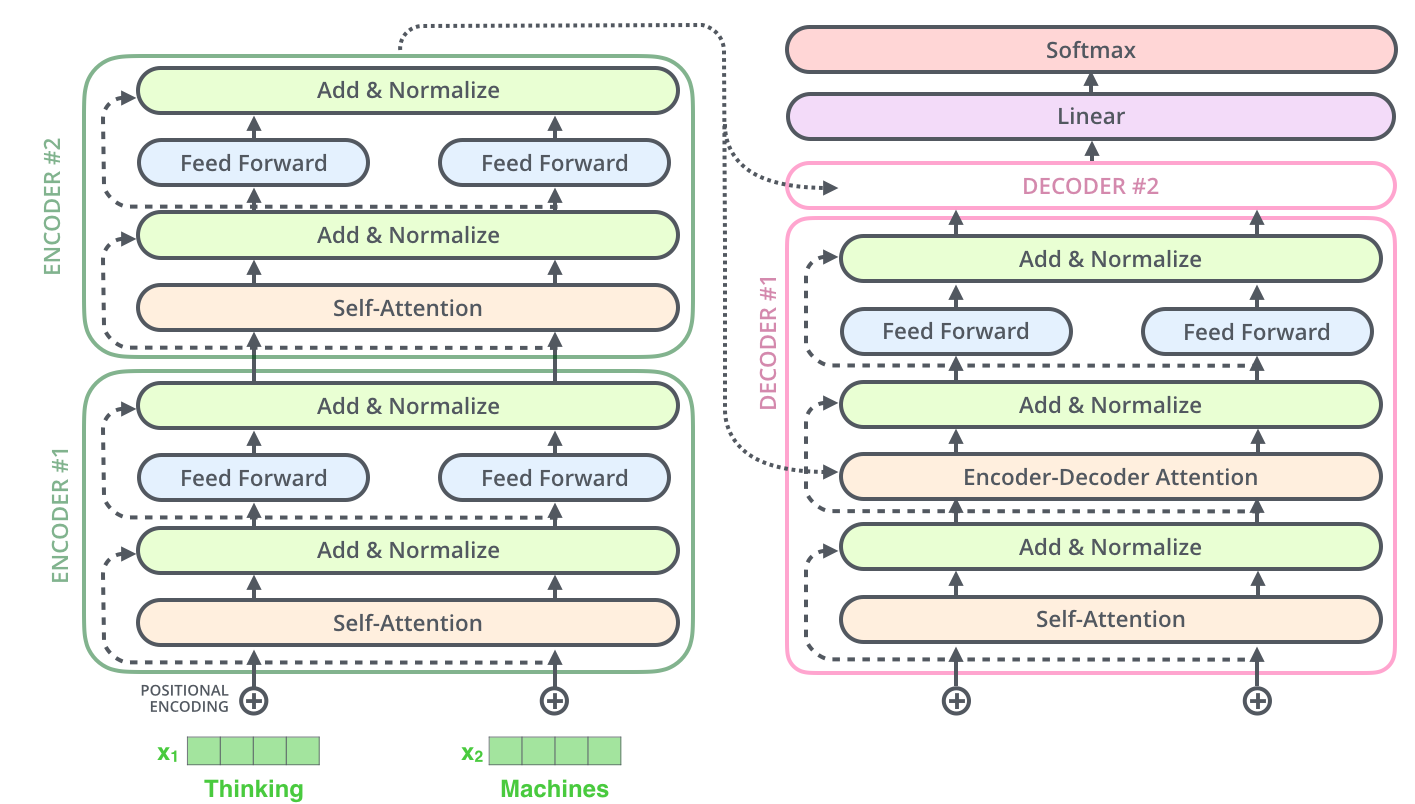
رمز گشا | The Decoder
در این بخش به توضیح ساختار رمزگشا یا همان decoder میپردازیم.
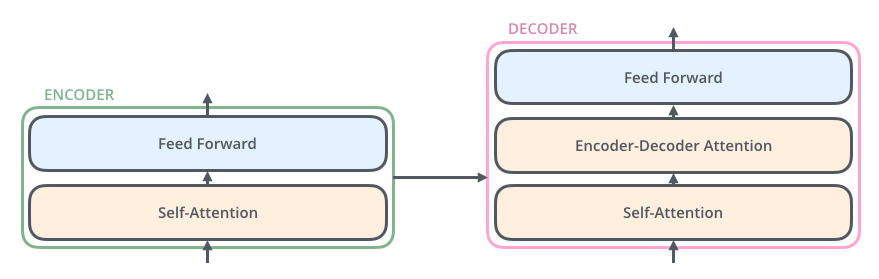
همانطور که دیدیم، رمزنگار (Encoder) در آخرین لایه خود مجموعهای از بردارهای توجه K و V را تولید میکند. این بردارها به تمام لایههای رمزنگار در بخش Decoder ورودی داده میشوند. با این کار رمزگشا میداند که بر کدام بخشهای جمله تمرکز کند.
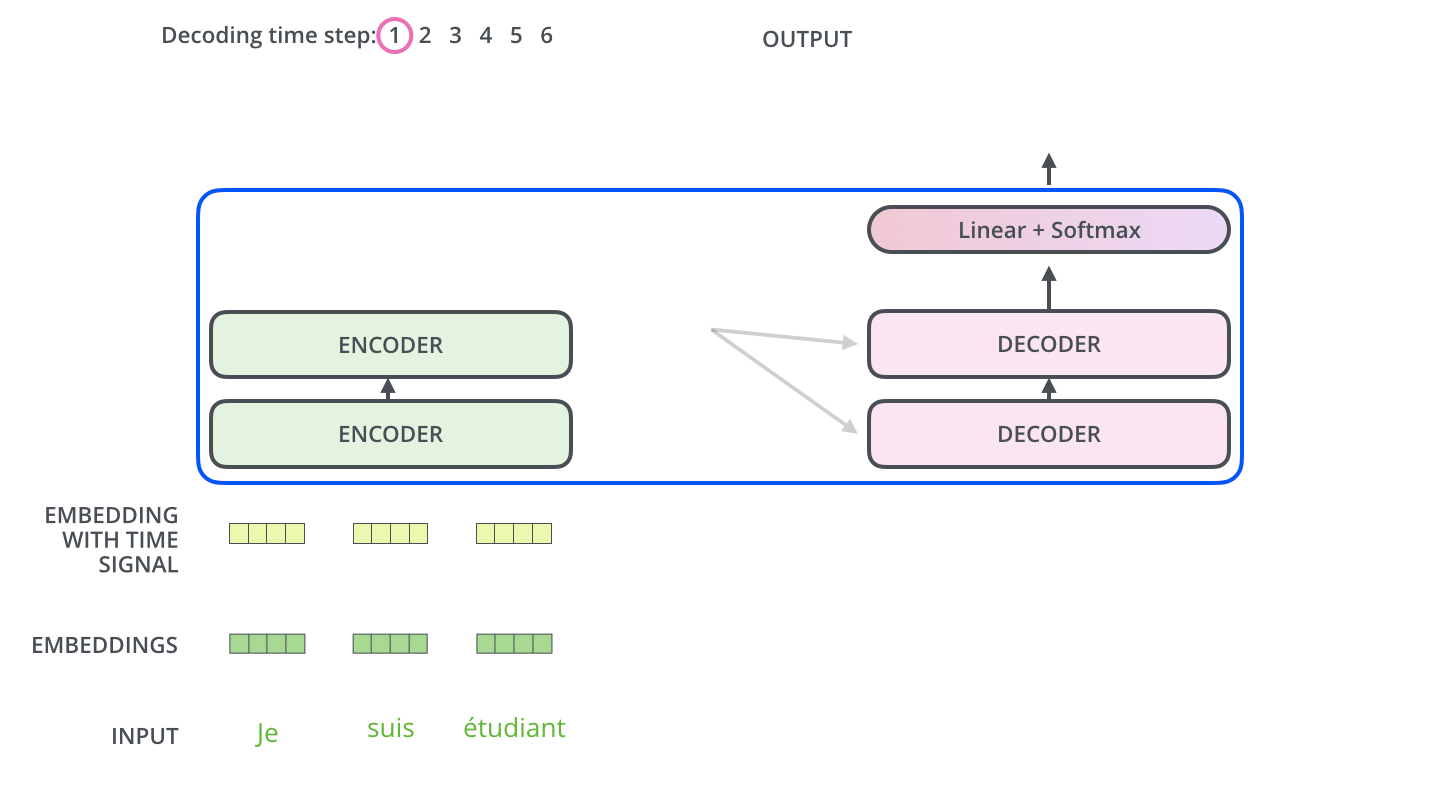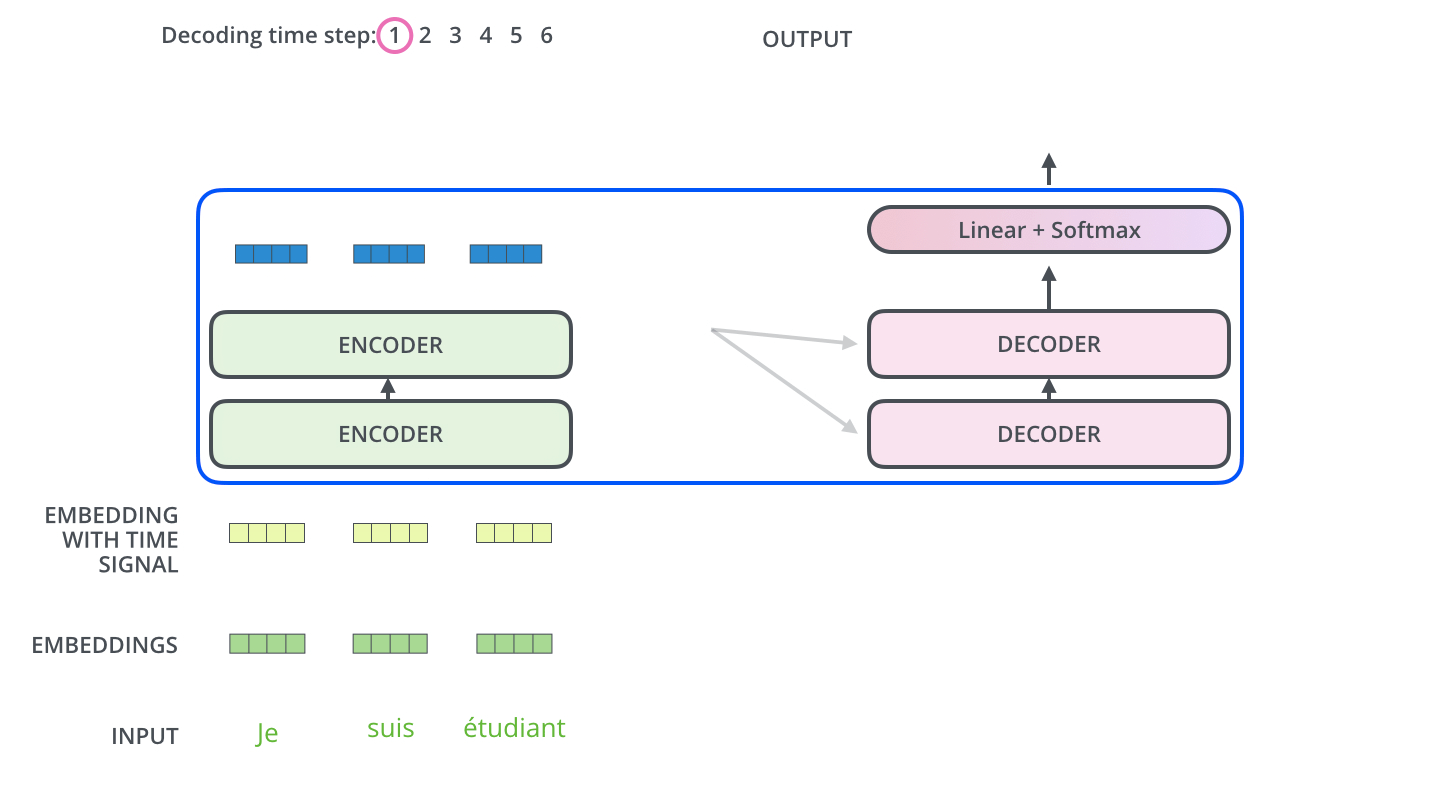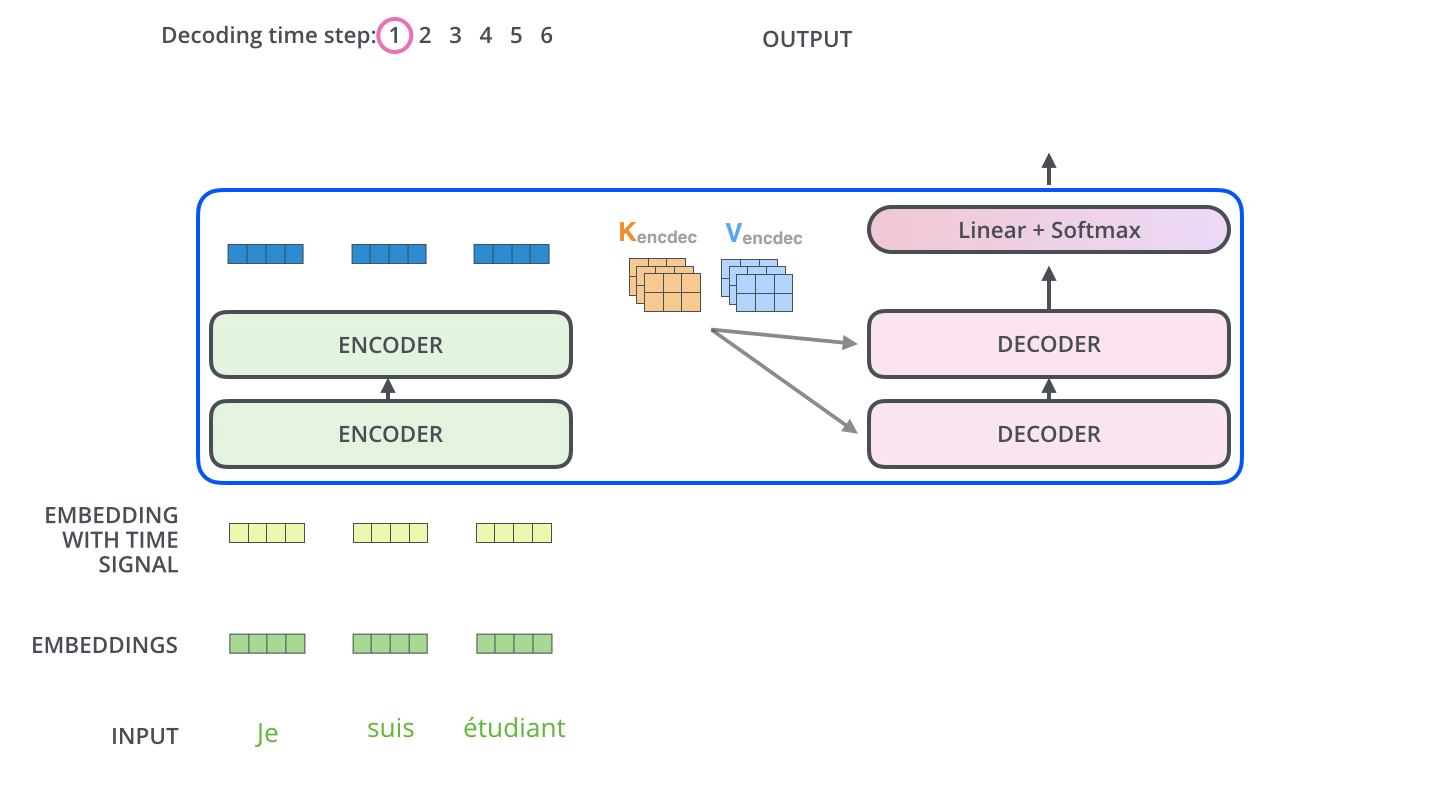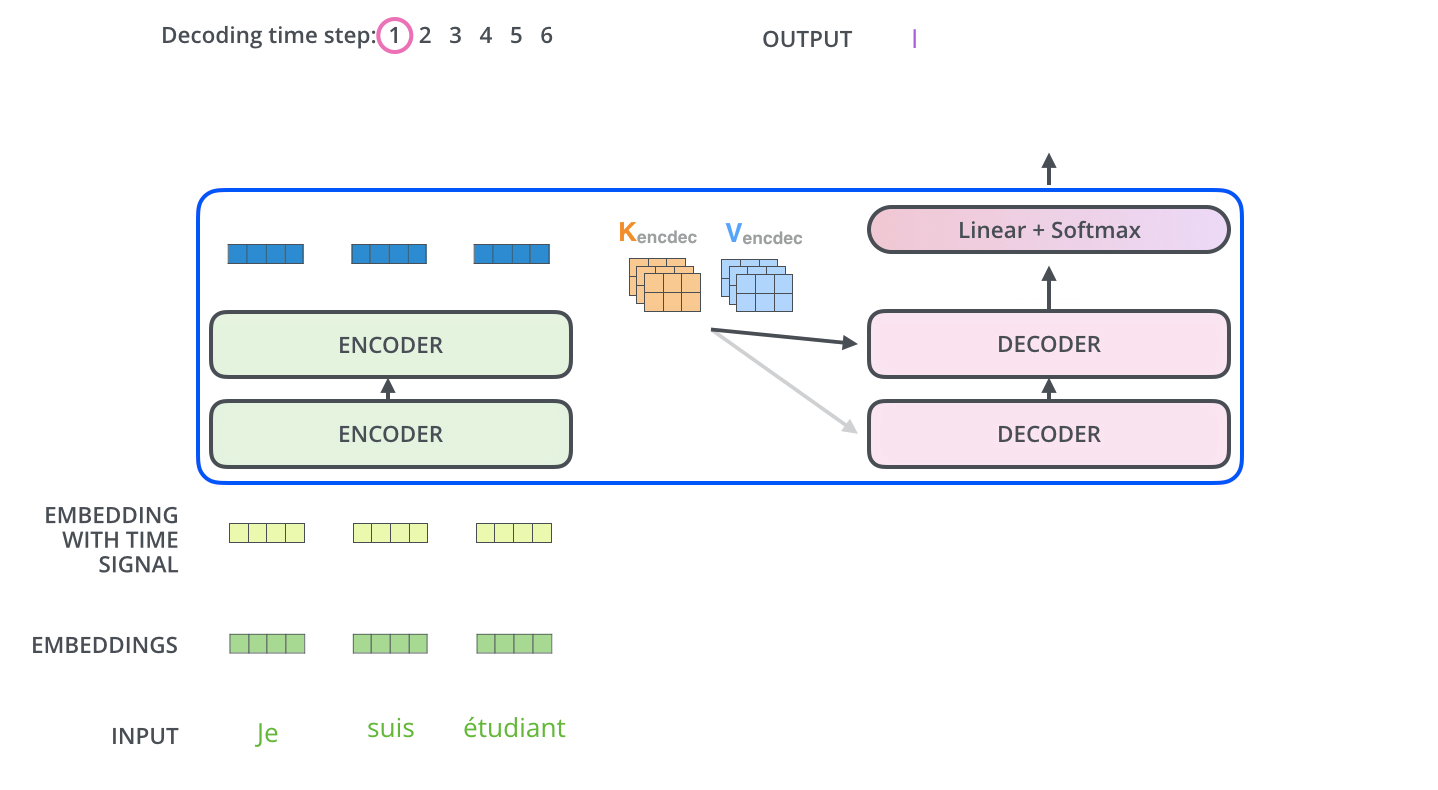
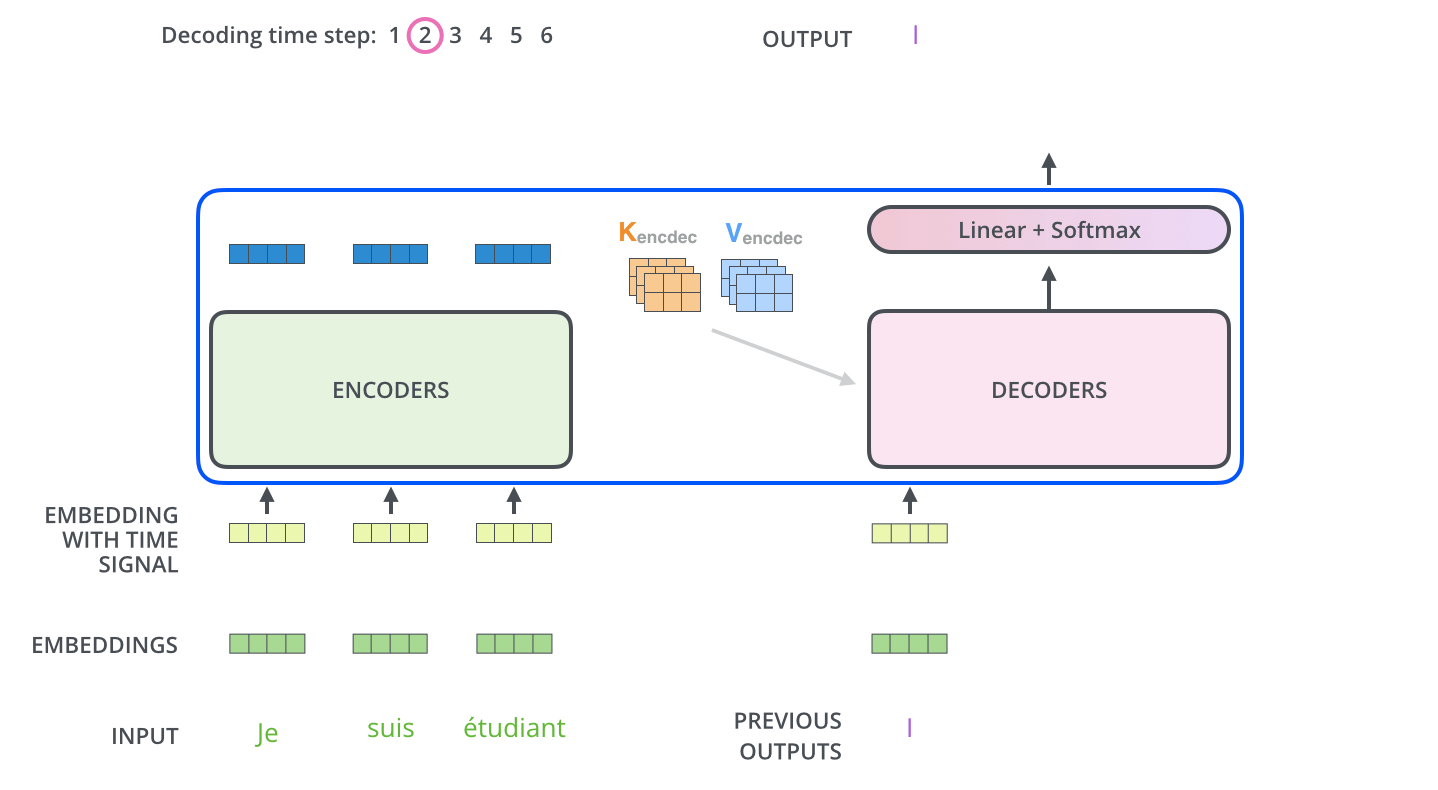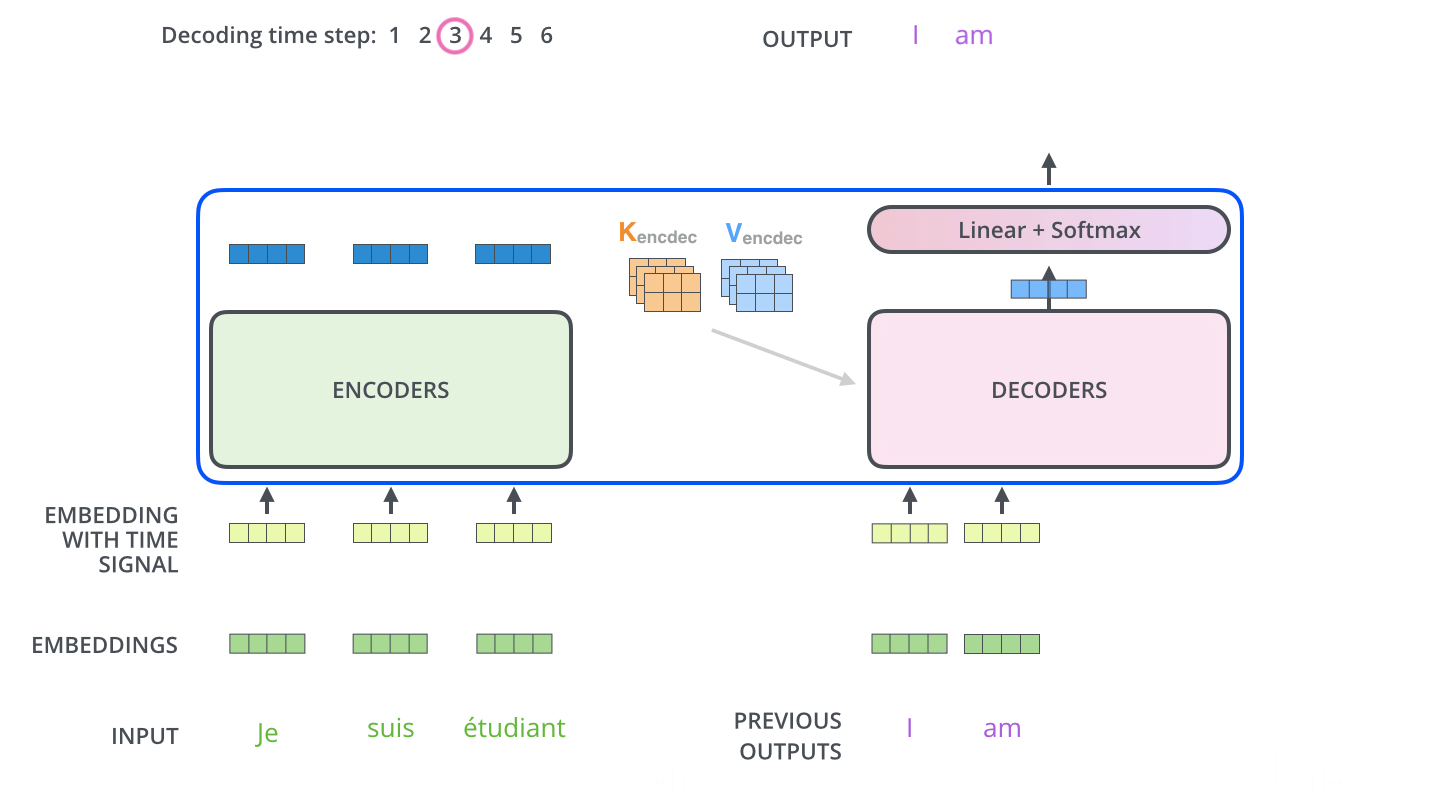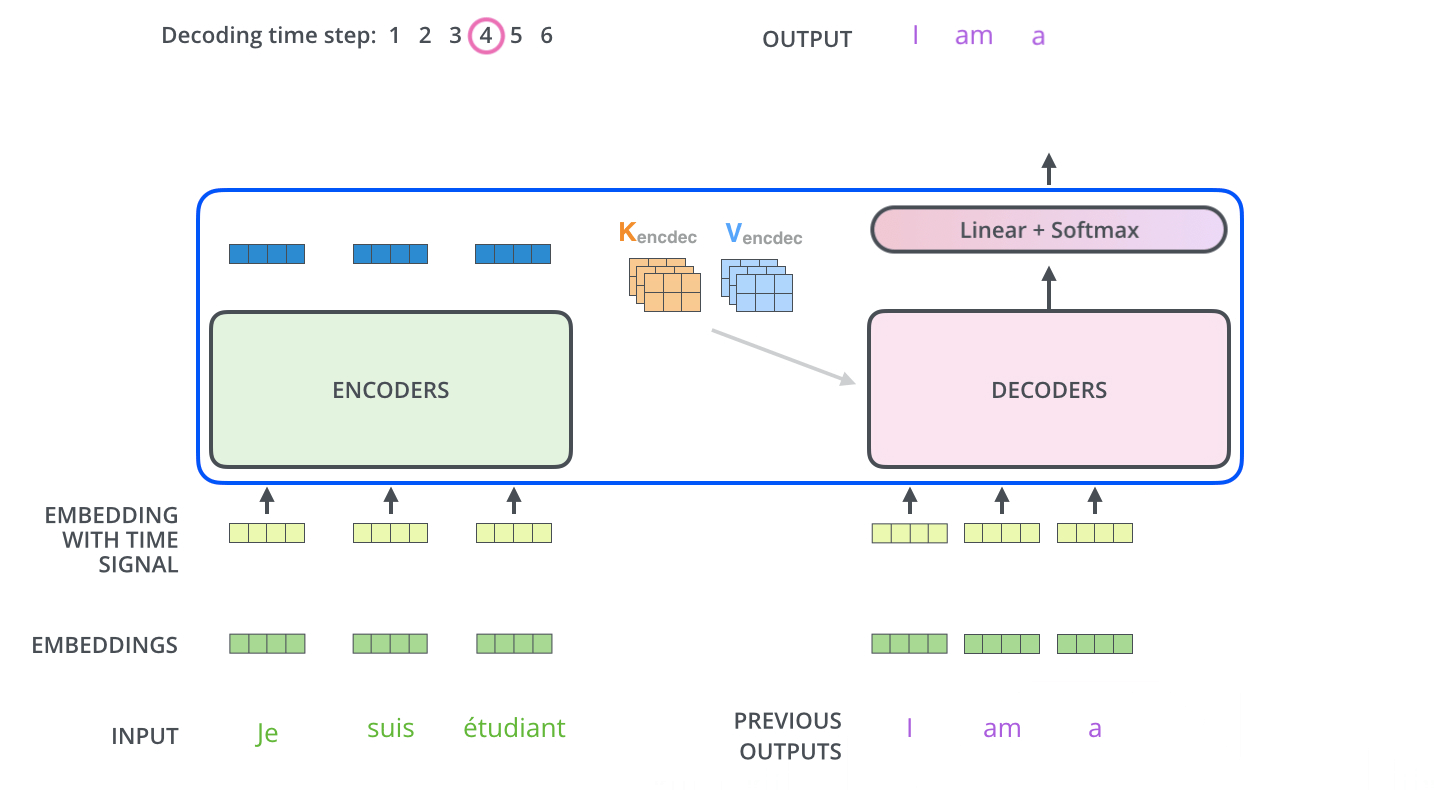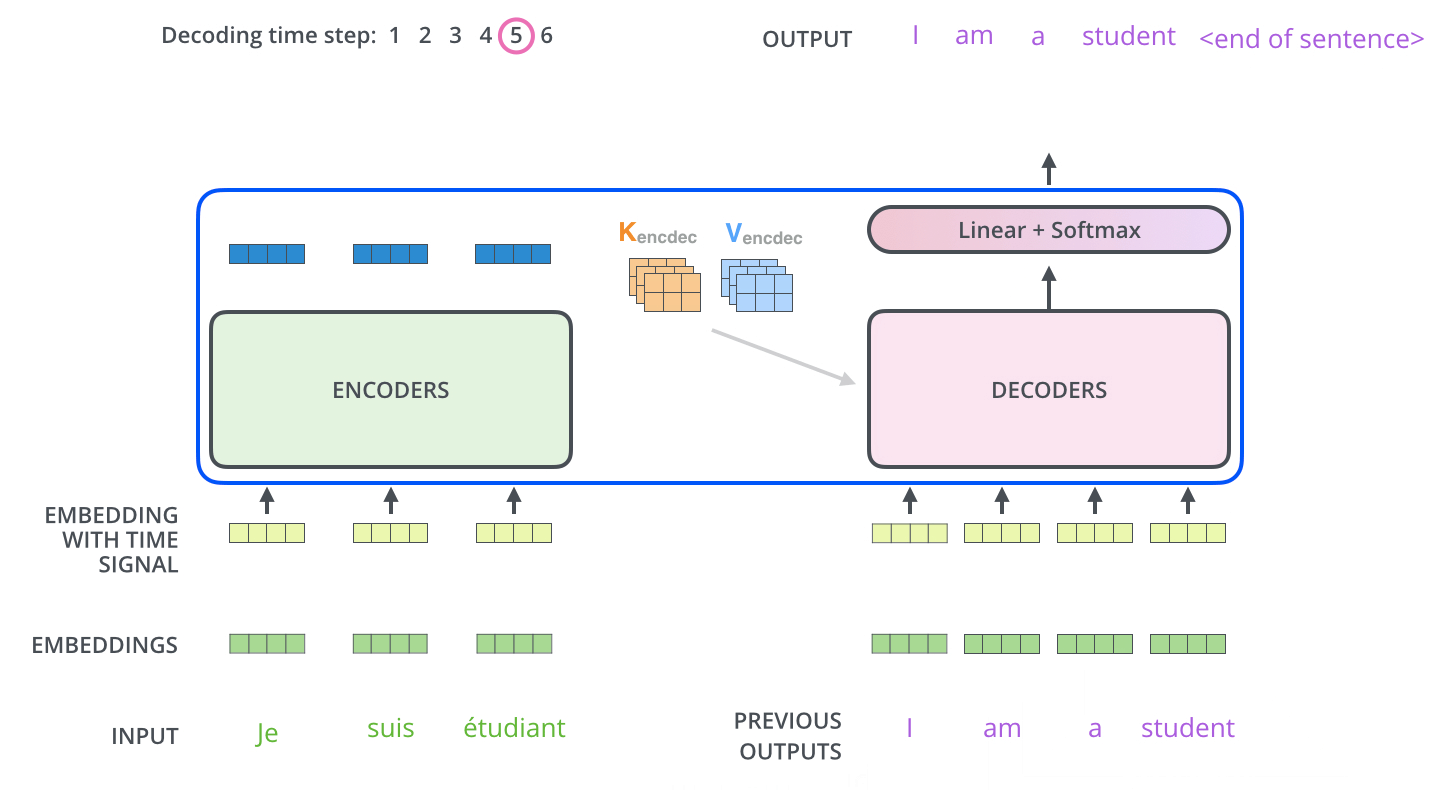
عملیات خود-توجه در رمزگشا به شکلی کمی متفاوت با آنچه در رمزنگار وجود دارد عمل میکند:
در رمزگشا، لایه خود-توجه تنها مجاز است به موقعیتهای قبلی در توالی خروجی توجه کند. این کار با مخفی کردن موقعیتهای آینده (تنظیم آنها به -inf) قبل از مرحله softmax در محاسبه خود-توجه انجام میشود.
لایه “Encoder-Decoder Attention” مشابه لایه خود-توجه چندسر عمل میکند، به جز این که ماتریس Queries خود را از لایه زیرین خود میسازد و ماتریسهای Keys و Values را از خروجی استک رمزنگار میگیرد.
لایه خطی و softmax آخر
خروجی نهایی رمزگشا (decoder) یک بردار عددی است. یک لایه Linear به همراه تابع فعالسازی softmax این اعداد را به کلمه تبدیل میکند.
لایه Linear آخر در واقع یک شبکه عصبی تمام متصل است که بردار خروجی رمزگشا را به یک بردار بسیار بزرگتر که شامل احتمالات اختصاص یافته به کلمات مختلف در vocabulary داده آموزش است. به این بردار بردار Logits نیز گفته میشود. برای مثال فرض کنید اندازه vocabulary 10000 کلمه باشد. در اینصورت اندازه بردار Logits که خروجی لایه خطی است دارای 10000 المان است. تابع فعالسازی softmax نیز این امتیازات را نرمالیزه میکند به طوریکه جمع همه این اعداد برابر با 1 شود. المانی که بیشترین احتمال برایش پیشبینی شده باشد انتخاب شده و به عنوان خروجی آن timestep در نظر گرفته میشود.
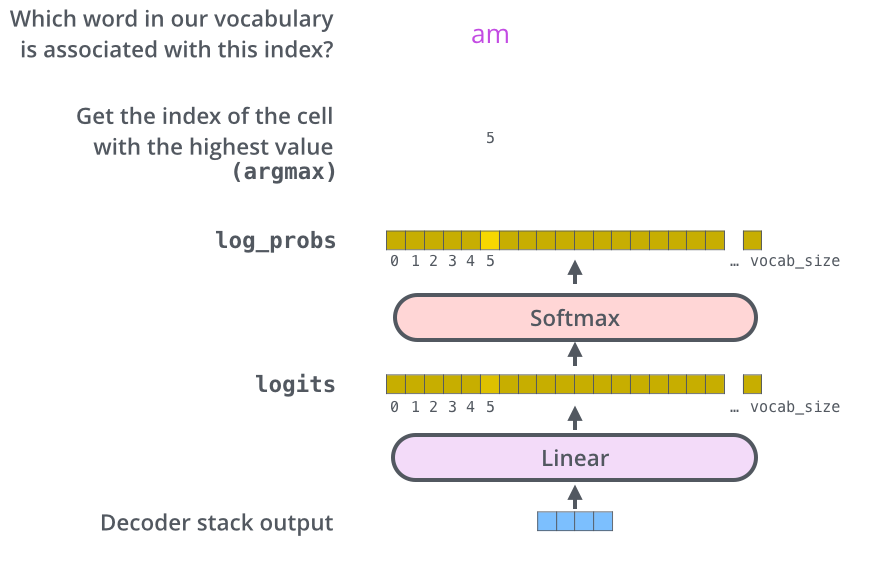
مرور آموزش
اکنون که کل فرآیند گذر از شبکهی پیشبینی یک ترنسفورمر آموزشدیده را پوشش دادهایم، مرور شهودی از آموزش مدل میتواند مفید باشد.
در طول آموزش، یک مدل آموزشندیده نیز دقیقاً همین گذر رو به جلو را تجربه میکند. اما از آنجا که ما آن را بر روی یک مجموعه دادهی آموزشی با برچسب آموزش میدهیم، میتوانیم خروجی آن را با خروجی صحیح واقعی مقایسه کنیم.
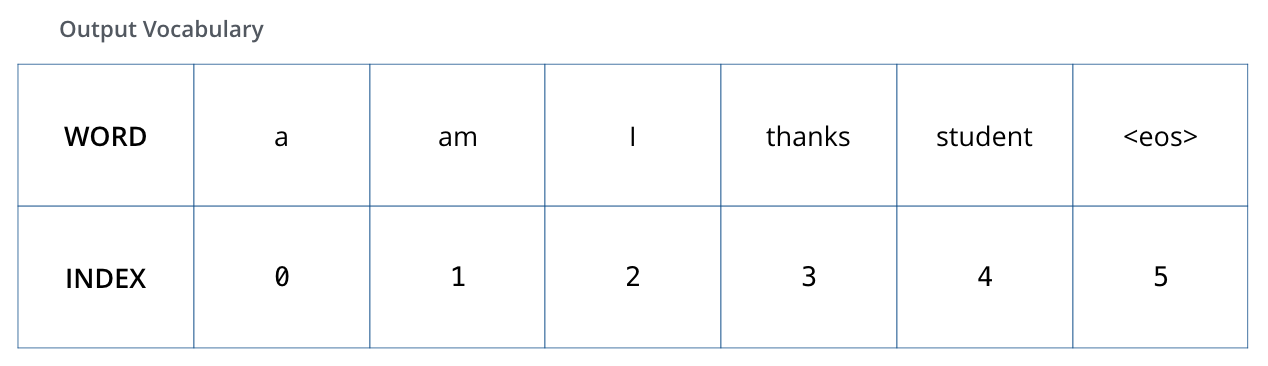
برای تجسم این موضوع، فرض کنیم که واژگان خروجی ما فقط شامل شش کلمه است (“a”، “am”، “i”، “thanks”، “student”، و "
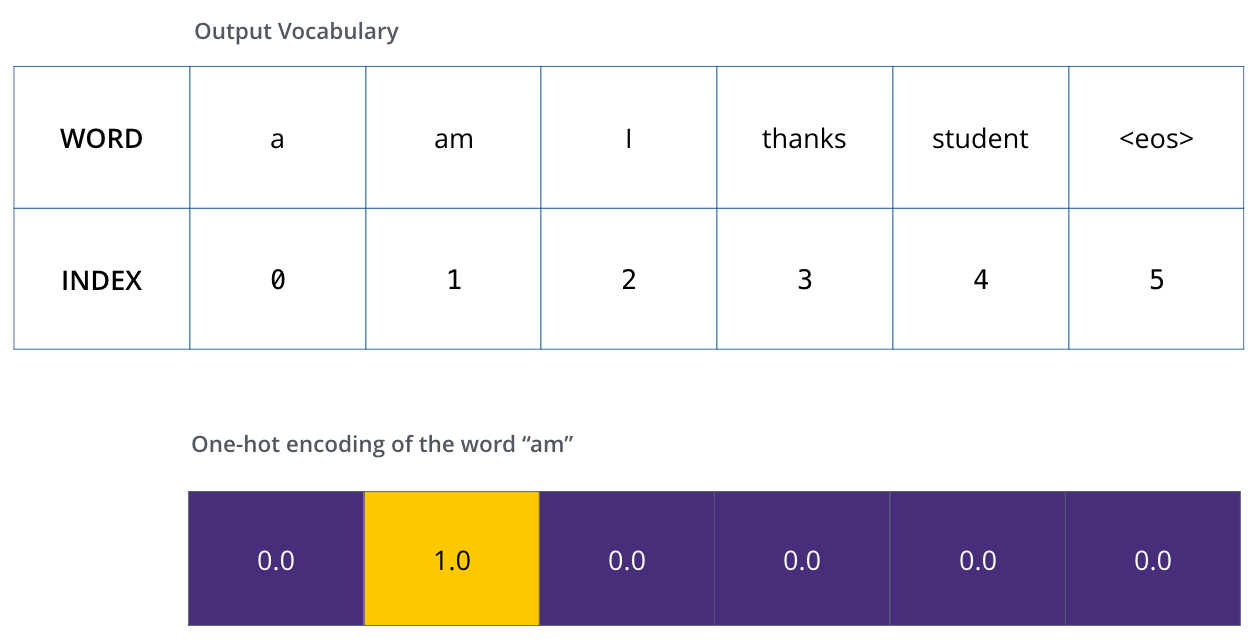
پس از تعریف واژگان خروجی، میتوانیم از یک بردار با همان عرض برای نشان دادن هر کلمه در واژگانمان استفاده کنیم. این روش همچنین به عنوان کدگذاری تکمقداری یا one-hot encoding شناخته میشود. بنابراین، به عنوان مثال، میتوانیم کلمه “am” را با استفاده از بردار زیر نشان دهیم:
پس از این مرور، بیایید در مورد تابع خطای مدل صحبت کنیم - معیاری که در طی مرحلهی آموزش برای بهینهسازی مدل استفاده میکنیم تا به یک مدل آموزشدیده و بسیار دقیق دست یابیم.
تابع خطا
فرض کنید در حال آموزش مدل خود هستیم. فرض کنید این اولین قدم ما در مرحلهی آموزش است و در حال آموزش مدل با یک مثال ساده هستیم – ترجمه “merci” به “thanks”.
این بدان معناست که ما میخواهیم خروجی یک توزیع احتمالی باشد که کلمه “thanks” را نشان میدهد. اما از آنجا که این مدل هنوز آموزش ندیده است، احتمالاً این اتفاق هنوز رخ نمیدهد.
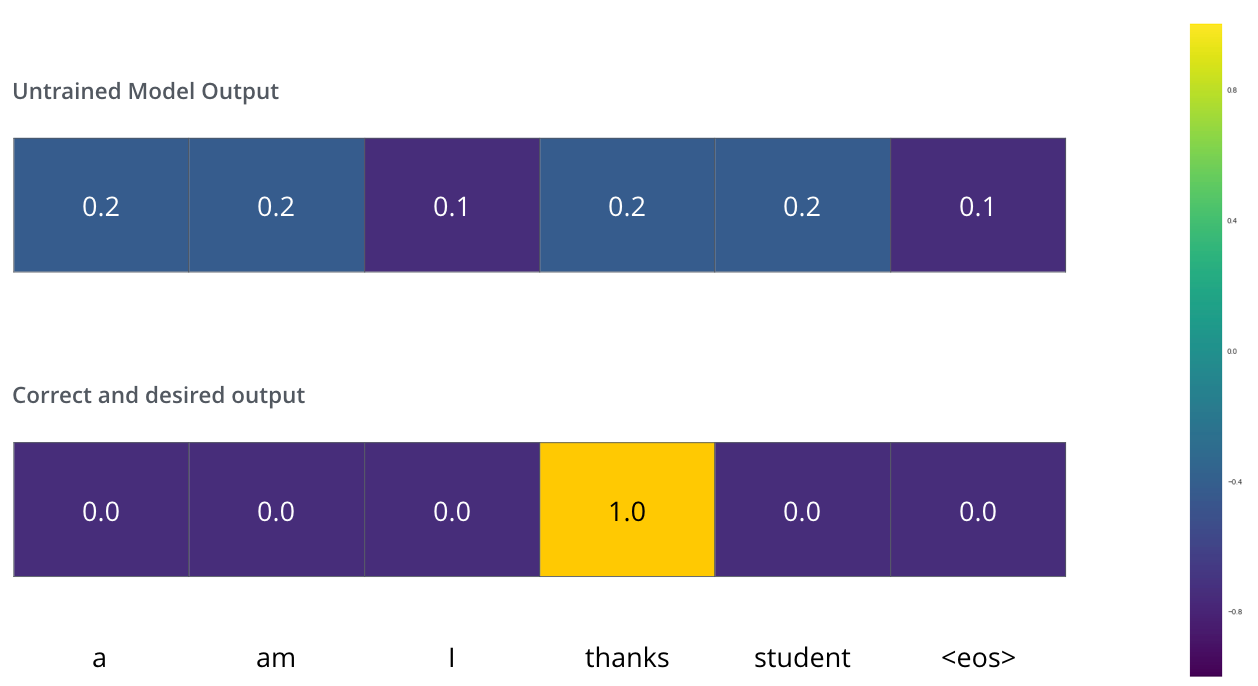
از آنجا که پارامترهای مدل (وزنها) بهصورت تصادفی مقداردهی اولیه شدهاند، مدل (آموزشندیده) یک توزیع احتمالی با مقادیر دلخواه برای هر سلول/کلمه تولید میکند. ما میتوانیم آن را با خروجی واقعی مقایسه کرده و سپس تمام وزنهای مدل را با استفاده از الگوریتم پسانتشار خطا تغییر دهیم تا خروجی به خروجی مطلوب نزدیکتر شود.
چگونه میتوان دو توزیع احتمالی را مقایسه کرد؟ بهسادگی یکی را از دیگری کم میکنیم. برای جزئیات بیشتر، به cross-entropy و Kullback–Leibler divergence مراجعه کنید.
اما توجه داشته باشید که این یک مثال بیشازحد سادهشده است. در واقعیت، ما از جملهای طولانیتر از یک کلمه استفاده خواهیم کرد. به عنوان مثال – ورودی: “je suis étudiant” و خروجی مورد انتظار: “i am a student”. این به این معنی است که ما میخواهیم مدل ما به طور پیوسته توزیعهای احتمالیای تولید کند که:
- هر توزیع احتمالی با یک بردار با عرض vocab_size (در مثال سادهی ما 6، اما در واقعیت رقمی مثل 30,000 یا 50,000) نشان داده میشود.
- اولین توزیع احتمالی، بالاترین احتمال را در سلولی که با کلمه “i” مرتبط است، دارد.
- دومین توزیع احتمالی، بالاترین احتمال را در سلولی که با کلمه “am” مرتبط است، دارد.
- و به همین ترتیب، تا زمانی که توزیع خروجی پنجم، نماد “پایان جمله” را نشان دهد که آن هم سلولی مرتبط با خود در میان واژگان 10,000 عنصری دارد.
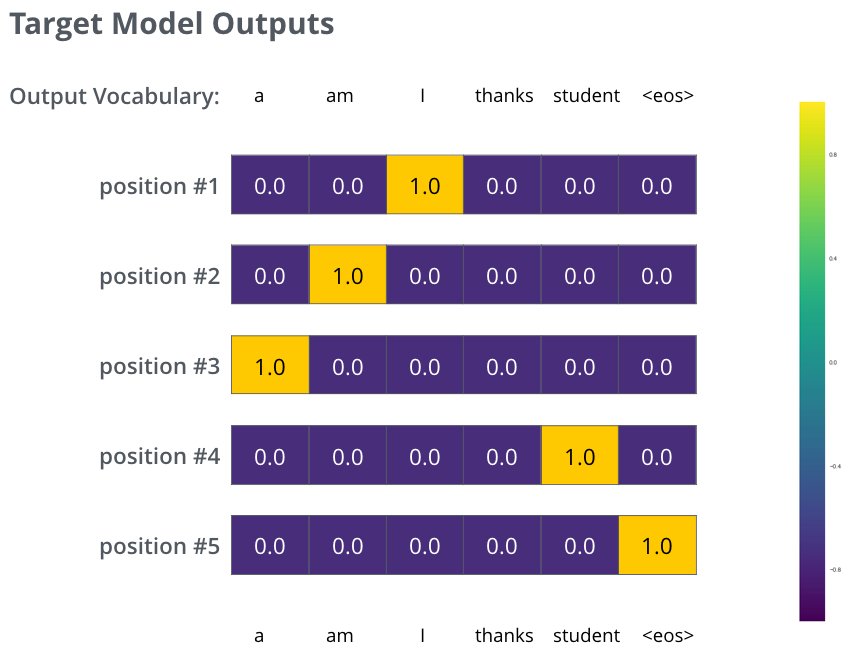
پس از آموزش مدل به مدت کافی و بر روی یک مجموعه دادهی به اندازه کافی بزرگ، امیدواریم که توزیعهای احتمالی تولیدشده به این شکل باشند:
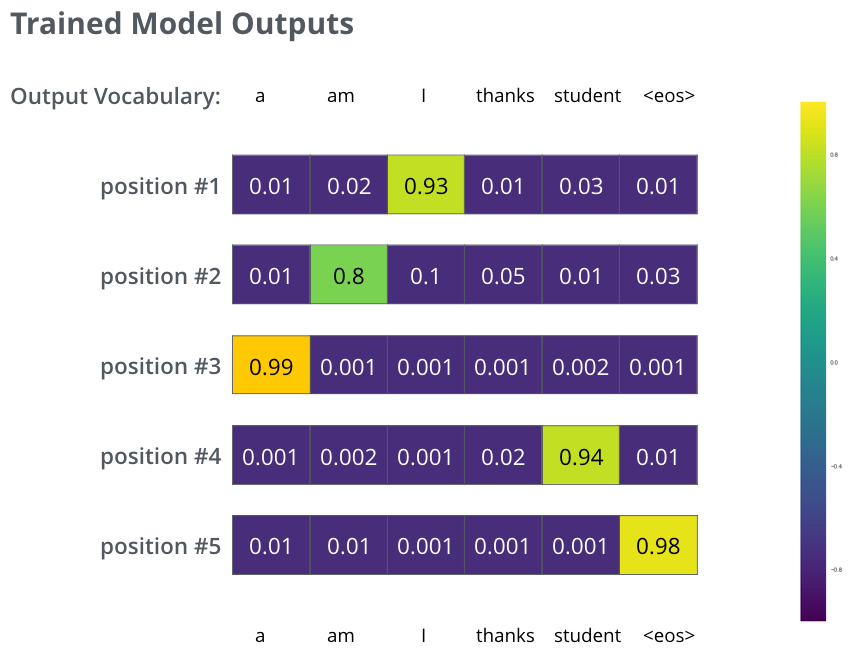
امیدواریم پس از آموزش، مدل خروجی ترجمهی درستی را که انتظار داریم تولید کند. البته، اگر این عبارت بخشی از مجموعه دادهی آموزشی بوده باشد، این موضوع نشانهی واقعی از عملکرد مدل نیست (see: cross-validation). توجه کنید که هر موقعیت حتی اگر خروجی آن در آن مرحله زمانی بعید باشد، مقدار کمی احتمال دریافت میکند — این یک ویژگی بسیار مفید از softmax است که به فرآیند آموزش کمک میکند.
اکنون، به دلیل اینکه مدل خروجیها را یکییکی تولید میکند، میتوانیم فرض کنیم که مدل در هر مرحله کلمهای با بالاترین احتمال را از آن توزیع احتمالی انتخاب کرده و بقیه را کنار میگذارد. این یکی از روشهای انجام این کار است (که به آن “کدگذاری حریصانه” گفته میشود). روش دیگر این است که فرض کنیم دو کلمهی اول (مثلاً “I” و “a”) با بالاترین احتمال انتخاب شدهاند، سپس در مرحله بعد، مدل را دوباره دو بار اجرا کنیم: یک بار با فرض اینکه موقعیت اول خروجی کلمهی “I” بوده و بار دیگر با فرض اینکه موقعیت اول خروجی کلمهی “a” بوده است، و نسخهای که خطای کمتری در نظر گرفتن هر دو موقعیت #1 و #2 تولید کرد، حفظ میشود. این روند را برای موقعیتهای #2 و #3 و… ادامه میدهیم. این روش “جستجوی پرتو” نامیده میشود که در مثال ما، beam_size دو بود (یعنی در هر زمان، دو فرضیهی جزئی (ترجمههای ناتمام) در حافظه نگهداری میشوند) و top_beams نیز دو بود (یعنی ما دو ترجمه بازگشتی خواهیم داشت). اینها هر دو هایپرپارامترهایی هستند که میتوانید با آنها آزمایش کنید.
Go Forth And Transform
امیدوارم با خواندن این مقاله درک خوبی نسبت به ساختار و نحوه عملکرد ترنسفورمر پیدا کرده باشید. اگر تمایل به مطالعه بیشتر دارید میتوانید از منابع زیر کمک بگیرید:
- Read the Attention Is All You Need paper, the Transformer blog post (Transformer: A Novel Neural Network Architecture for Language Understanding), and the Tensor2Tensor announcement.
- Watch Łukasz Kaiser’s talk walking through the model and its details.
- Play with the Jupyter Notebook provided as part of the Tensor2Tensor repo.
- Explore the Tensor2Tensor repo.
در ادامه می توانید مقالات زیر را نیز بخوانید:
- Depthwise Separable Convolutions for Neural Machine Translation
- One Model To Learn Them All
- Discrete Autoencoders for Sequence Models
- Generating Wikipedia by Summarizing Long Sequences
- Image Transformer
- Training Tips for the Transformer Model
- Self-Attention with Relative Position Representations
- Fast Decoding in Sequence Models using Discrete Latent Variables
- Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
تشکر و قدردانی
باتشکر از JayAlammar.